
MemGPT
本文内容主要参考论文 [1]
1 背景与问题
LLM虽然革命性地改变了AI,但受限于固定长度的上下文窗口。如果简单拓展上下文长度,会因为Transformer 的自注意力机制导致与计算时间、内存呈二次方增长。所以memory机制就十分重要
2 MemGPT 系统设计
它主要是借鉴操作系统虚拟内存的概念:
-
操作系统通过"分页"在物理内存和硬盘之间交换数据,让应用程序以为有无限内存
-
是不是也可以 LLM 在有限的上下文窗口(内存)和外部存储(硬盘)之间自动"换页",营造出无限上下文的幻觉?具体的设计如下图:
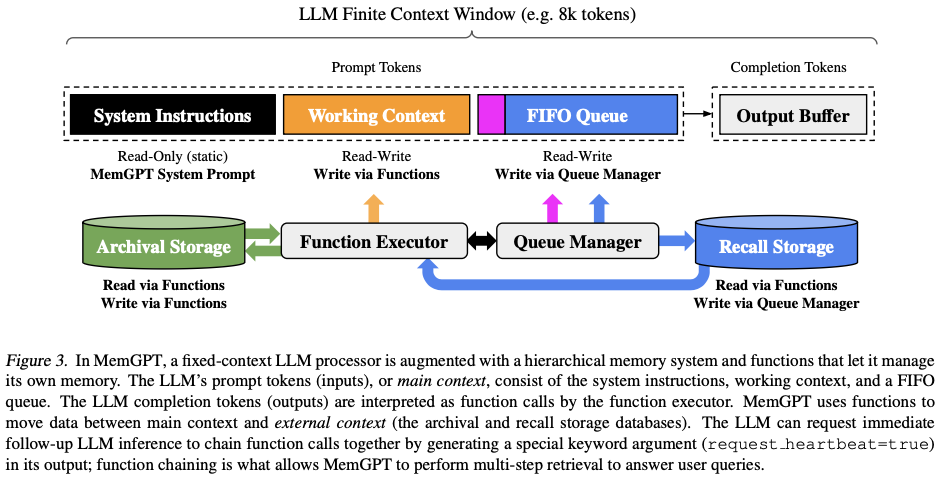
2.1 Prompt组成
LLM 的Prompt被划分为三个连续区域:
| 区域 | 功能 |
|---|---|
| 系统指令(System Instructions) | 包含规则。只读 |
| 工作上下文(Working Context) | 存储关键事实、用户偏好、角色设定等结构化信息。可读写 |
| FIFO 队列 | FIFO 队列的第一个位置保存一个递归摘要,用于快速回顾已被逐出的旧消息, 其他位置滚动存储最近的消息历史,包括对话、系统警告、函数调用记录等。可读写 |
2.2 函数执行器(Function Executor)
整个系统主要通过LLM选择使用Function Executor来完成增删改查,LLM 自己决定何时读取/写入外部存储、修改工作上下文,并且输出将被解析为函数调用,函数执行结果(包括错误信息)会反馈给 LLM,让它调整后续行为。
下图主要展示了LLM通过调用读函数改变了FIFO队列的内容:

下图主要展示了LLM通过调用写函数改变了working context和FIFO队列的内容:

2.2 队列管理器(Queue Manager)
队列管理器主要是负责管理消息在 FIFO 队列之间的流动新消息,消息进入 FIFO 队列时,同时写入 Recall Storage; 当提示词超过上下文窗口的70% 时,插入系统警告,提醒 LLM 主动保存重要信息到工作上下文或归档存储; 当达到 100% 上限时,逐出 50% 的旧消息,生成新的递归摘要,被逐出的消息永久存入 Recall Storage
2.4 控制流与函数链(Control Flow & Function Chaining)
-
事件驱动:用户消息、系统警告、定时事件等触发 LLM 推理
-
函数链:LLM 可以在一次用户交互中连续执行多个函数(如先搜索文档,再翻页,再综合回答),通过
request_heartbeat=true标志请求立即继续推理
3 实验
3.1 实验设置
3.1.1 baseline与实现
本文主要选用当时的三种主流大语言模型作为 MemGPT 的底层处理器进行实验: GPT-3.5 Turbo,GPT-4和GPT-4 Turbo
对于固定上下文基线模型,当输入长度超过其上下文窗口时,采用**截断(truncation)策略处理检索到的文档;对于对话任务,基线模型通过递归摘要(recursive summarization)**获取历史会话信息,以模拟现有长对话系统的常见做法。
MemGPT 的外部存储采用 PostgreSQL 数据库,向量检索(archival里存的是用户上传的pdf和一些外部文档,可能过长所以需要向量检索)通过 pgvector 扩展实现,使用 HNSW 索引 支持近似最近邻搜索,文档嵌入统一采用 OpenAI 的 text-embedding-ada-002模型。
3.1.2 数据集
- 对话代理数据集:采用 Xu 等人提出的 Multi-Session Chat数据集,该数据集主要包含由人工标注者生成的多轮对话日志,每个对话者需在全部会话中保持固定人设。原始数据集包含 5 个会话,每轮约十余条消息。本文在此基础上扩展了第 6 会话,用于回忆前5轮对话的深度记忆,并将人设提炼到对话开场白以用来对应人物的测试。
- 文档分析数据集:采用 NaturalQuestions-Open 数据集的子集(50 个问题),配套使用 2018 年底 Wikipedia 语料库作为检索源。所有文档预先计算嵌入向量并加载至归档存储。
- 嵌套键值检索数据集:基于 Liu 等人提出的合成 KV 检索任务扩展得到。本文构造了 嵌套 KV 数据集:每个键和值为 128 位 UUID,且值本身可能也是键,要求代理执行多跳查找。
3.1.3 评估指标
- **对话任务:
- 深度记忆检索(DMR):采用 ROUGE-L Recall(R) 和 LLM-as-a-Judge 准确率。评判标准由 GPT-4 担任裁判,判断生成回答是否与标准答案在主题上一致。
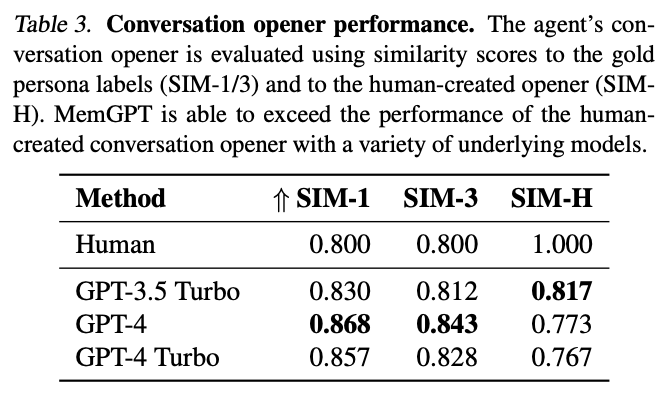
- 对话开场白:采用 SIM-1 / SIM-3(与黄金人设标签的相似度)和 SIM-H(与人类撰写开场白的相似度)进行自动评估。、
- 文档分析任务:采用 LLM-as-a-Judge 准确率,要求模型同时给出答案和引用文档原文,防止模型利用参数知识而非检索文档作答。
- 嵌套 KV 检索:采用准确率,以最终返回的 UUID 是否匹配标准答案为准。
3.2 实验结果
3.2.1 对话代理实验
-
深度记忆检索任务(DMR):结果表明,MemGPT 显著提升了所有底层模型的记忆一致性。

-
对话开场白任务:实验发现,MemGPT 生成的开场白不仅覆盖更多人设维度,且有时超过人类撰写基线的 SIM-H 分数。
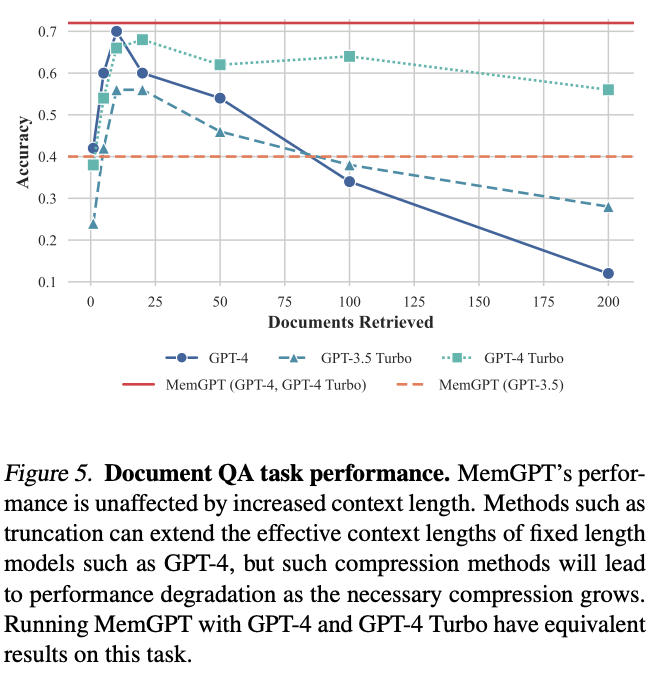
3.2.2 文档分析实验
测试模型在检索文档数量 增加时的鲁棒性。发现MemGPT准确率几乎不受文档数量影响,始终维持在高水平。
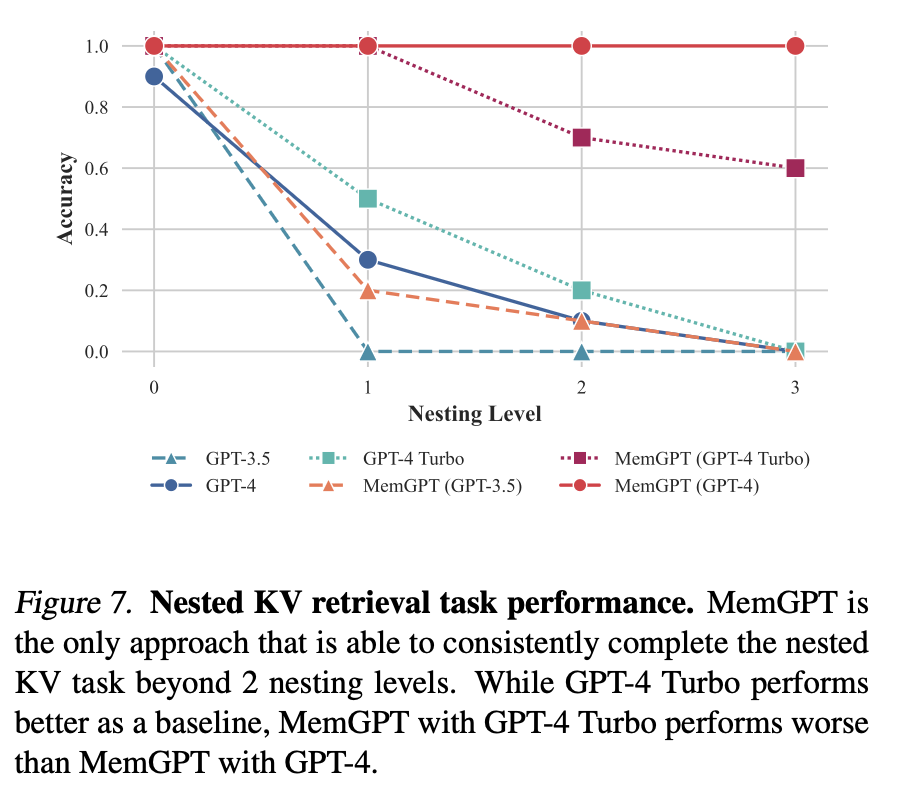
3.2.3 嵌套键值检索实验
测试模型从多个数据源中整合信息的能力。每增加一层嵌套,就需要额外一次 KV 查找。
4 总结与感想
memory是今年的热点话题,在这个领域MemGPT应该算是早一点的一批论文了。在这篇文章中,我们可以简单看到短期(FIFO)和长期记忆(Working Context)的雏型,也可以看见关键词匹配的局限性。顺便一提,MemGPT这篇论文已经被论文作者拿去创业,叫做Letta,有兴趣的小伙伴可以去支持一下。
Packer C, Fang V, Patil S G, et al. MemGPT: towards LLMs as operating systems[J]. 2023. ↩︎


