
Mem0
本文主要参考论文[1]
1 背景与问题
这里就比较常规,还是说LLM固定上下文窗口导致无法维持长期多会话对话的一致性,引出memory的重要性
2 方法
人类记忆的关键是选择性存储、整合关联概念、按需检索。Mem0 模仿这一过程,让 AI 代理动态提取、组织、检索对话中的关键信息,而不是简单地把所有历史塞进提示词。论文将memory管理和正常对话解耦,对于memory管理总共提出了两个方法,Mem0和Mem0g。在正常对话的时候只需要向量嵌入查询top s个相关的记忆就作为memory就可以了。
2.1 Mem0
如下图所示:
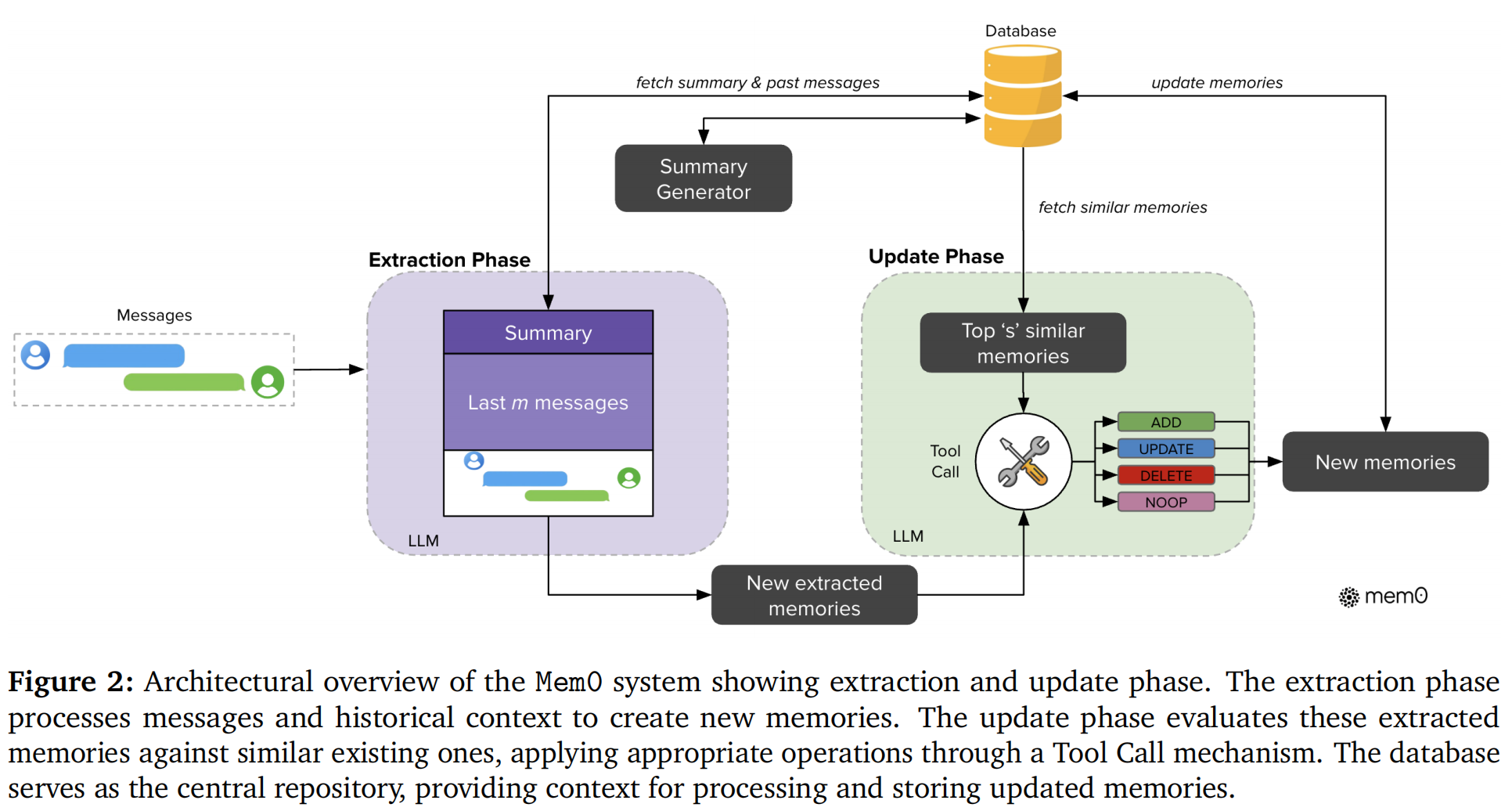
Mem0 的核心是两阶段流水线:提取阶段(Extraction Phase) 负责从对话中提炼事实,更新阶段(Update Phase) 负责把这些事实合并进长期记忆库。每收到一对新消息 时自动触发,通常 是用户消息, 是助手回复。
2.1.1 提取阶段
如上图紫色部分,输入提示词 主要包含三个信息源:对话摘要 (由独立的异步摘要生成器定期刷新,确保提取时能看到对话全貌),最近 条消息以及当前消息对 。
LLM 执行提取函数 ,输出一组候选记忆事实:
这些事实是自然语言形式的精简陈述,例如:
"用户是素食主义者,不吃乳制品""用户下周三要去旧金山出差"
关键设计:摘要生成器是异步运行的,与主流水线解耦,避免阻塞记忆提取。
2.1.2 更新阶段
对每个候选事实 ,系统用向量嵌入在数据库中检索 top 个语义相似的已有记忆(论文设 )。系统把"候选记忆事实 + 检索到的相似记忆"一起交给 LLM,LLM 通过 函数调用 选择以下四种操作之一:
| 操作 | 条件 | 动作 |
|---|---|---|
| ADD | 没有语义等价的已有记忆 | 创建新记忆条目 |
| UPDATE | 已有记忆存在,且新事实能补充/丰富它 | augmentation(合并信息) |
| DELETE | 新事实与已有记忆矛盾 | 删除旧记忆(如"喜欢咖啡"→"戒咖啡了") |
| NOOP | 事实已存在或无关紧要 | 不做任何修改 |
2.2 Mem0g
Mem0g 在 Mem0 基础上引入图结构记忆,把自然语言事实升级为实体-关系图,更好地捕捉复杂关联,每个节点 包含三个组件:实体类型:分类标签(Person, Location, Event 等),嵌入向量 :捕捉实体语义,用于相似度搜索,以及元数据:创建时间戳 ,具体如下图:
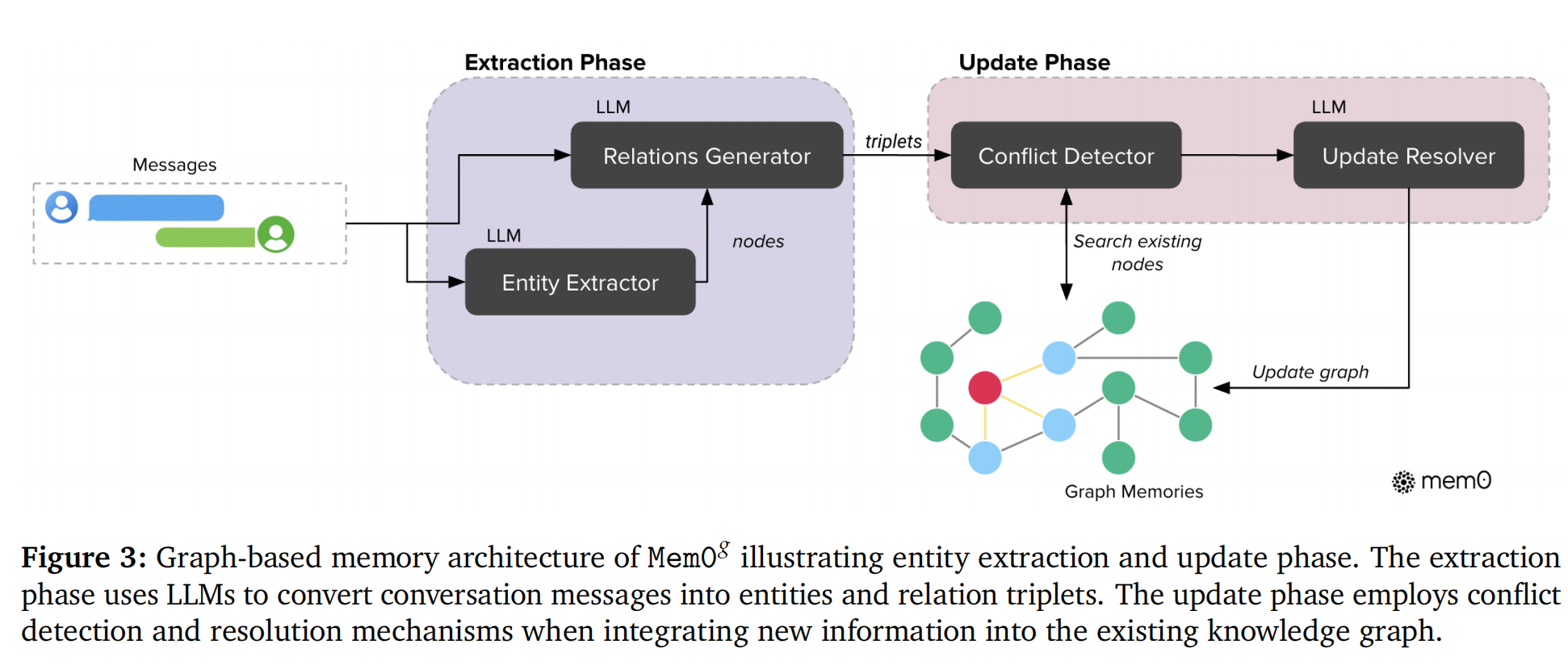
2.2.1 提取阶段
总共分为两阶段:
- 第一阶段:Entity Extractor(实体提取器):由 LLM 驱动,分析输入文本并识别所有值得存入记忆的实体及其类型
- 第二阶段:Relations Generator(关系生成器):分析已提取的实体及其在对话中的上下文并识别实体间的语义关联,输出关系三元组,例如:
(Alice, lives_in, San_Francisco)
2.2.2 更新阶段
当新信息到达时,Mem0g 的更新和 Mem0 类似,但是这部分最大的区别在于没有LLM参与,而是在现有图中搜索语义相似度超过阈值 的节点,再根据匹配结果决定:创建新节点、复用已有节点、或部分匹配
注意当新关系与图中已有关系矛盾时(如用户先说"住纽约",后说"搬去旧金山"),系统不物理删除旧关系,而是标记旧关系为"失效"(obsolete)。这样做的好处在于保留了时间线和历史状态并支持时间推理(如回答"你之前住哪里?"),避免信息永久丢失
3 实验
3.1 实验设置
3.1.1 baseline与实现
baseline主要选择如下:
- LOCOMO 已有的几个常见基准:LoCoMo,ReadAgent,MemoryBank,MemGPT,A-Mem
- 开源记忆方案:用了LangChain 生态的记忆架构LangMem(Hot Path),使用 GPT-4o-mini + text-embedding-small-3
- RAG: 将整段对话历史视为文档,切分为固定长度块(128, 256, 512, 1024, 2048, 4096, 8192 tokens),使用 OpenAI
text-embedding-small-3做嵌入,检索时取 top 块(), 时最多 16,384 tokens,系统评估不同 chunk size 和 值的组合 - 全上下文处理:直接将对话历史塞进 LLM 上下文作为"理论上限"参考
- OpenAI ChatGPT Memory: 使用 ChatGPT 内置 memory 功能(gpt-4o-mini),将整段对话一次性导入,让系统自动提取记忆
- 记忆管理平台(Memory Providers):使用商业记忆管理平台Zep
3.1.2 数据集
主要用的LOCOMO数据集,问题分为Single-hop(答案在单轮对话中),Multi-hop(答案在多轮对话中),Temporal(设计时间顺序),Open-domain(依赖外部知识回答)四类
3.1.3 评估指标
论文采用如下评估:
- F1 Score / BLEU-1:论文指出了这个指标的严重缺陷:对事实错误不敏感。例如标准答案是"Alice 生于三月",系统回答"Alice 生于七月",两者词汇高度重叠(Alice、born、in),传统指标会给出高分,但事实完全错误。
- LLM-as-a-Judge:用更强的 LLM(GPT-4o-mini)作为裁判,评判生成回答的事实准确性,相关性,完整性和上下文适当性。由于 LLM 评判具有随机性,论文对每个方法跑 10 次独立实验,报告均值 ± 标准差。
- Token Consumption:使用
cl100k_base(tiktoken)编码测量检索阶段送入 LLM 的上下文 token 数,对记忆类模型检索到的记忆事实的 token 数,对 RAG 类模型:检索到的文本块的 token 数 - Latency:Search latency负责检索记忆(或文本块)的耗时,Total latency:检索 + LLM 生成答案的总耗时,报告 p50(中位数) 和 **p95(95分位)**来反映典型表现和尾部延迟
3.2 实验结果
3.2.1 记忆系统性能对比
具体实验结果如下图:
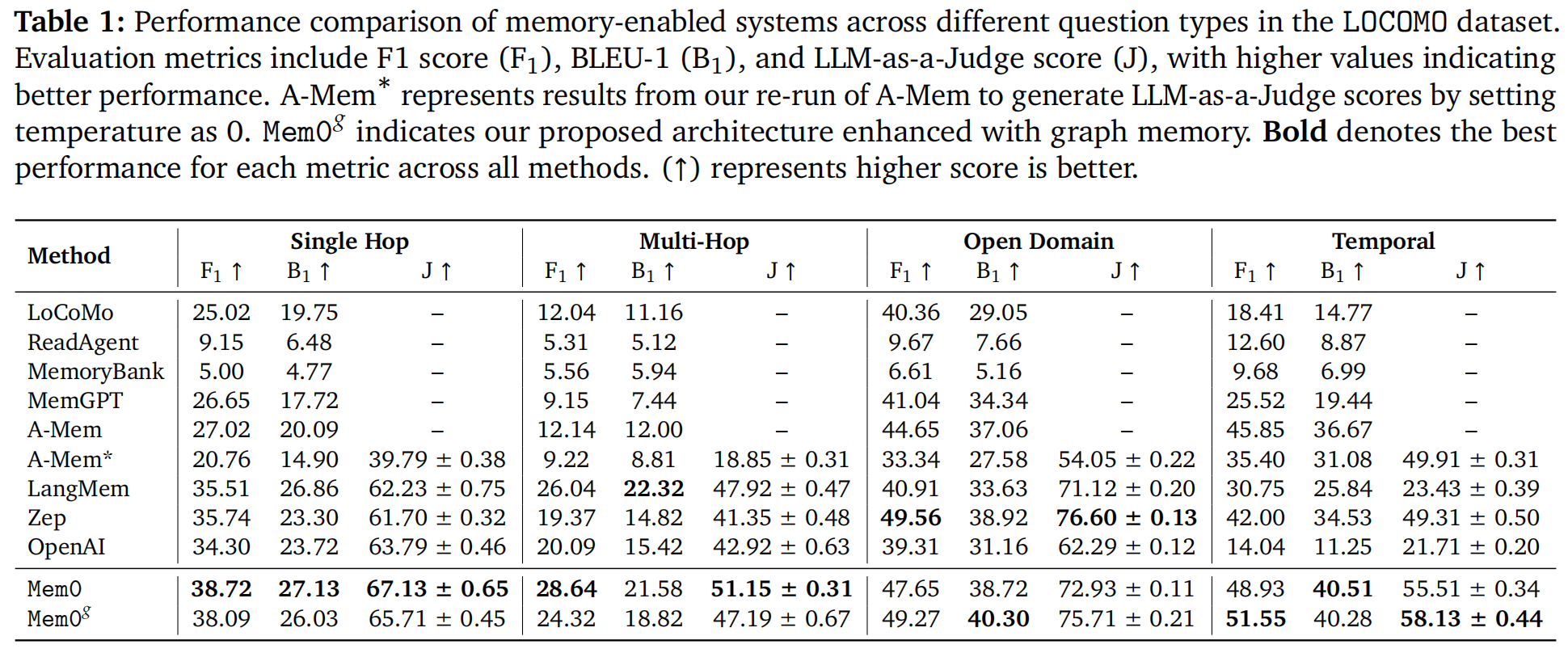
Single-hop,Multi-hop都是Mem0 最优,得益于其密集自然语言记忆结构,简洁的事实表示直接匹配查询无需遍历复杂结构。Open-domain是Zep 最优,优势可能来自其更丰富的外部知识整合机制,Temporal是Mem0g 最优,图结构对时间关系和事件序列的建模优势明显。
论文原以为图结构会帮助多跳推理,但实验显示 Mem0g反而低于 Mem0。说明图遍历可能引入不必要的中间节点增加噪声,而自然语言记忆的直接语义匹配更高效。另外ChatGPT memory 的提取机制未保留时间戳,导致等相对时间无法解析。
3.2.2 与 RAG 和全上下文对比
具体实验结果如下图:
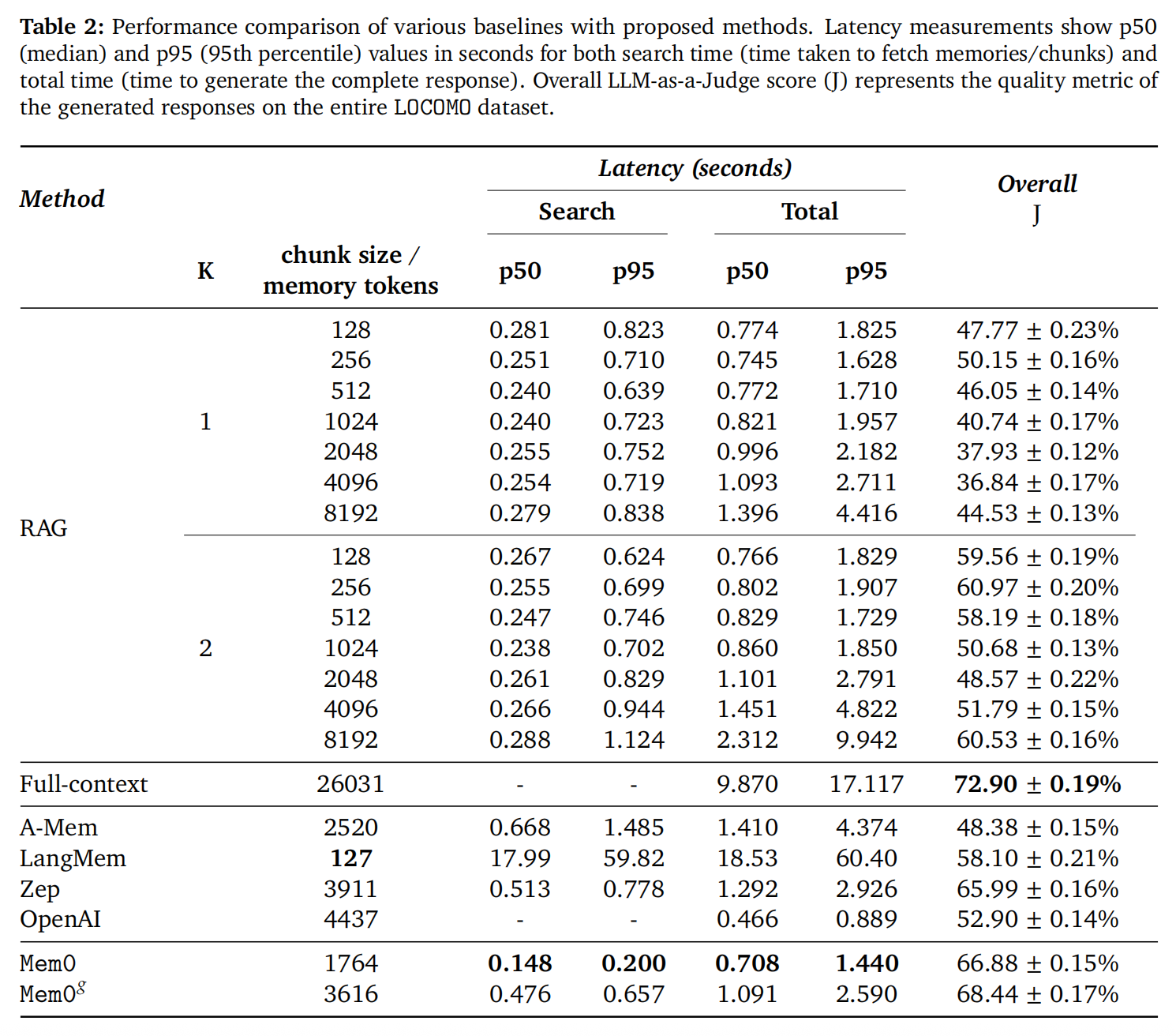
- RAG 的局限:最优 RAG 配置(chunk=8192, k=2)整体 J 仅 61.0%,原因是大块原始文本包含大量噪声反而干扰 LLM 推理。具体现象来看随着 chunk size 增大,准确率反而下降
- 全上下文的局限:虽然因为保留了完整信息无损整体 J 最高,但 p95 总延迟 17.12 秒,无法用于实时交互,且Token 消耗成本极高
- Mem0和Mem0g的取舍:Mem0g的准确率更高,但是延迟也更高,在需要高准确率的场景值得接受额外开销
3.2.3 延迟分析
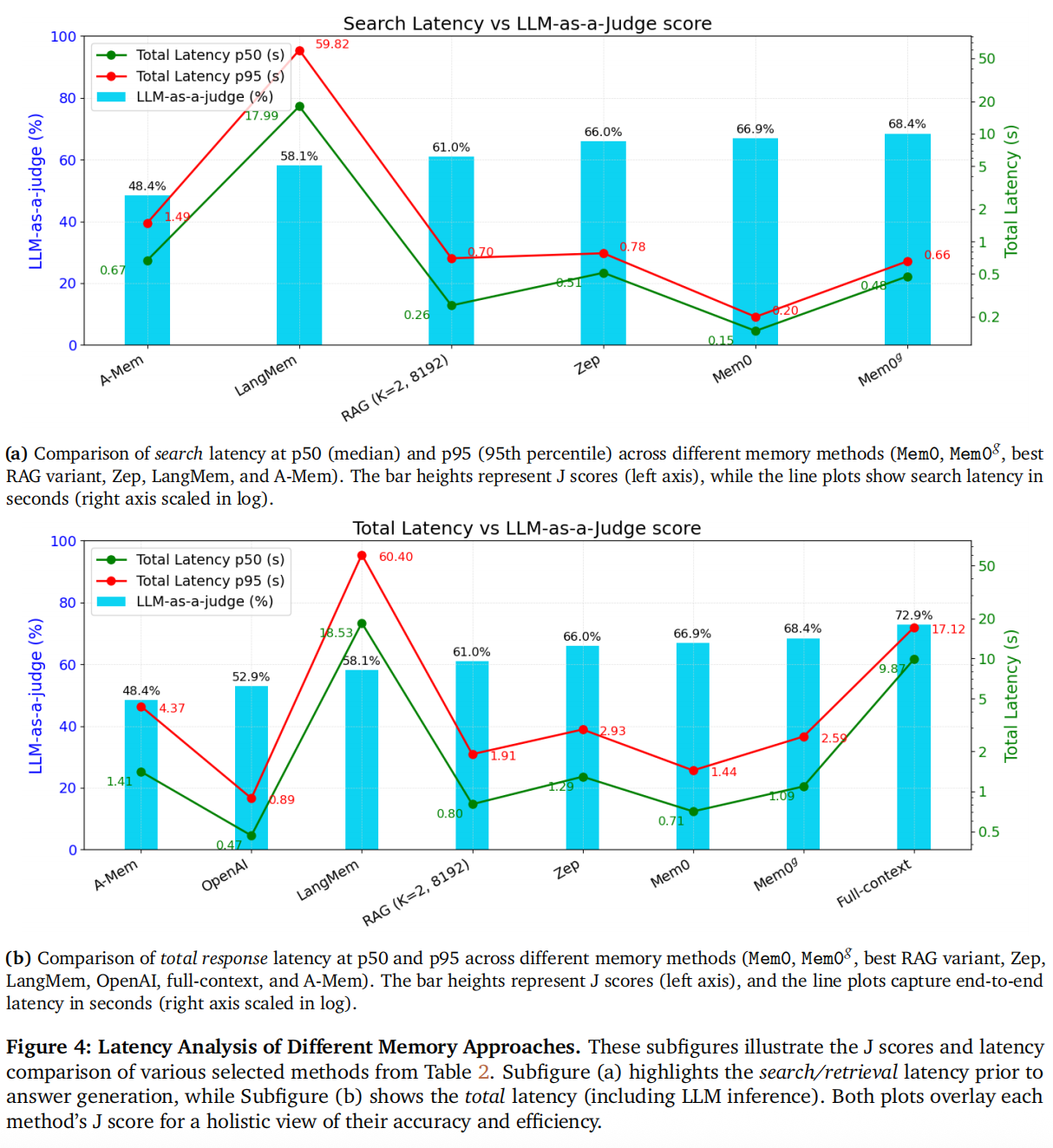
- 搜索延迟:Mem0 搜索延迟最低,原因是只检索精简的记忆事实而非固定大小文本块
- 总延迟对比:OpenAI 总延迟最低,但这是因为它不需要实时检索而是预先把所有记忆加载好,而Mem0 总延迟在实时系统中极具竞争力
3.2.4 Token分析
在 token 效率上,在原始对话26000 tokens的基础上,Zep 每次对话开销超过 600k tokens,是 Mem0 大约7k token的 85 倍,根本原因是 Zep 在每个节点缓存完整摘要、边上又存事实,信息在图中大量重复。相比之下,Mem0 将 26k tokens 的原始对话压缩到 7k且信息无损,效率更高
更致命的是冷启动问题:Zep 添加记忆后需等待数小时后台处理才能正常查询,而 Mem0/Mem0g 图构建在 1 分钟内完成、新记忆立即可用。
4 总结与感想
最后Mem0提到未来方向是以下四点:
- 优化 Mem0g 的图操作:降低图记忆带来的延迟开销
- 探索分层记忆架构(hierarchical memory architectures):把检索效率和关系表示能力结合起来
- 开发更精细的记忆巩固机制:借鉴人类认知的遗忘与巩固过程
- 扩展到非对话场景:如多模态交互
Mem0相比前面的很多工作其实最大的区别在于他强制让memory管理和memory查询解除绑定了,对于查询只做了单独的向量检索,而对于记忆的管理却分为了Mem0和Mem0g两个工作。我个人觉得一是论文最后提到的多模态agent memory确实是一个很好的探索点,并且现在这方面的工作还不算多;二是其实memory的查询应该怎么查应该也可以更加细化,怎么查查什么或许可以成为未来工作的重点。
Chhikara P, Khant D, Aryan S, et al. Mem0: Building production-ready ai agents with scalable long-term memory[J]. arXiv preprint arXiv:2504.19413, 2025. ↩︎


