
Search-R1
本文主要来自论文[1]
1 背景
现有的检索增强生成(RAG)或工具调用提示(Prompting)方法通常不是最优的,因为大模型并没有在训练阶段真正学会如何与搜索引擎进行多轮的最优交互。为了解决这个问题,研究团队将搜索引擎直接建模为 RL 环境的一部分,让模型通过轨迹采样和试错来学习搜索策略。
2 方法
2.1 Loss Masking for Retrieved Tokens
在使用强化学习(如 PPO 或 GRPO 算法)训练模型时,模型生成的每一个 Token 通常都会被用来计算Loss并更新模型参数 。但这在“搜索+推理”的场景下会引发一个严重问题: 在生成序列中,既包含了大模型自己生成的推理过程,也包含了系统从外部搜索引擎抓取回来的文档内容 。如果把检索回来的文本也纳入优化计算,会导致模型产生难以预料的优化行为和学习动态 。
为了解决上述问题论文引入了“检索 Token 掩码”机制。在计算策略梯度时,系统只针对大模型自己生成的 Token计算损失,而将检索回来的外部文档 Token通过掩码彻底屏蔽。这种设计能够防止检索内容对策略优化产生不良干扰,极大地提升了强化学习训练的稳定性,同时又保留了模型利用搜索内容生成答案的灵活性 。
2.2 Multi-Turn Interleaved Reasoning and Search
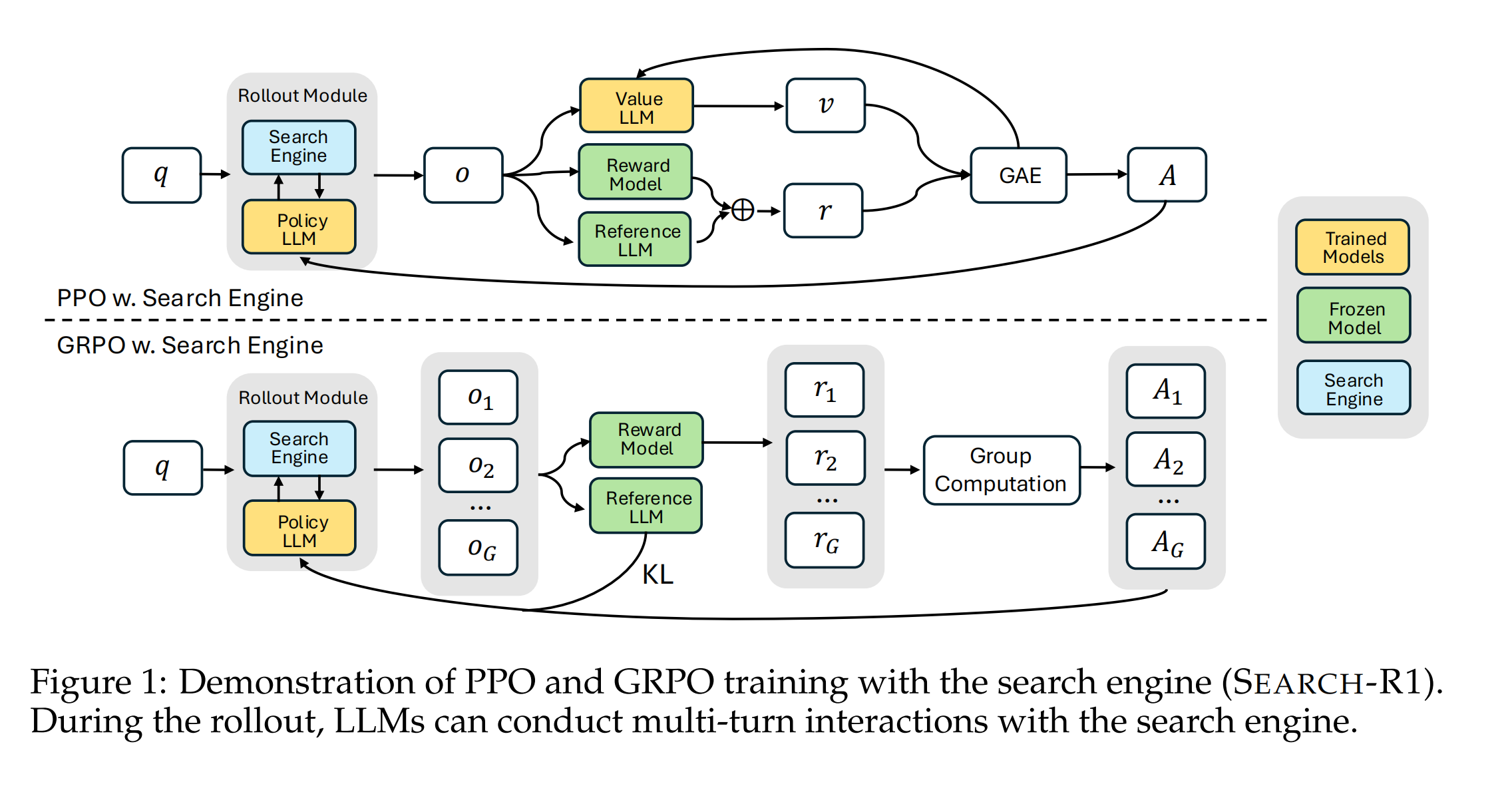
传统的 RAG通常是单向的:用户提问 -> 检索一次资料 -> 模型根据资料生成一次回答 。而 SEARCH-R1 则赋予了模型“多轮自主检索”的能力,让大模型在“自我文本生成”和“外部搜索引擎查询”之间交替迭代 。方法具体流程如上图,这种工作过程是通过下述的一套特殊的标签符号来实现结构化控制的:
- 内部推理 (
<think>):在回答问题或获取新信息后,模型必须首先在<think>和</think>标签内进行逻辑推理 。 - 发起搜索 (
<search>):如果模型在推理中发现自己缺乏某些知识,它会被触发输出类似<search> 关键词 </search>的指令 。 - 环境交互与信息注入 (
<information>):系统截获到搜索指令后,向搜索引擎发请求,并将返回的搜索结果包裹在<information>和</information>标签中,追加到当前对话里,作为大模型下一步思考的上下文 。 - 得出结论 (
<answer>):这个“推理-检索”的过程可以循环多次,直到达到设定的最大操作次数,或者模型认为信息已经充足,它就会在<answer>和</answer>标签内直接输出最终答案 。
2.3 Outcome-Based Reward Modeling)
在强化学习中,奖励函数(Reward Function)是指挥模型进化的“指挥棒” 。SEARCH-R1 采取了极其简单的路线:它完全摒弃了复杂的过程奖励,采用了一个基于规则的奖励系统,纯粹依靠最终答案的正确性来给模型打分 。例如,在事实类问答中,如果模型最终 <answer> 里的内容与标准答案完全匹配(精确字符串匹配),就能获得奖励 。另外Search-R1也没有做格式奖励,因为在纯结果导向的 RL 训练中,模型自己就能学习并展现出强大的格式遵循能力 。论文没有训练专门的神经网络来评估奖励。这不仅避免了引入额外的计算成本和系统复杂性,也防止了在大规模 RL 训练中大模型对特定形式奖励的过度敏感 。
3 结论与感想
Search-R1是agentic rl的一篇很经典的论文了,其内容在如今看来是很不完善的,比如最后没有用LLM-as-a-judge做奖励会有reward hacking风险,或者没有sft冷启动也没有格式奖励会不会乱。但是它的贡献主要是让模型与搜索引擎之间从单轮交互过渡到多轮交互从而改进回答质量。在信息搜索如此重要的当下,agentic的想法也是让他成为经典的一大原因。
Jin B, Zeng H, Yue Z, et al. Search-r1: Training llms to reason and leverage search engines with reinforcement learning[J]. arXiv preprint arXiv:2503.09516, 2025. ↩︎


