
H2O
本文主要参考论文H2O[1]
1 背景与问题
尽管LLMs能力强大,但部署成本极高,尤其是在处理长文本生成(如对话系统、故事创作)时,除了模型本身的参数外,KV Cache会随着序列长度和Batch Size的增加呈线性增长,显存占用则会急剧增加。 为了解决这个问题,作者提出了一种名为 (Heavy-Hitter Oracle) 的动态缓存淘汰策略,旨在大幅减少内存占用的同时保证模型生成的质量和准确率,具体方法Overview如下图:
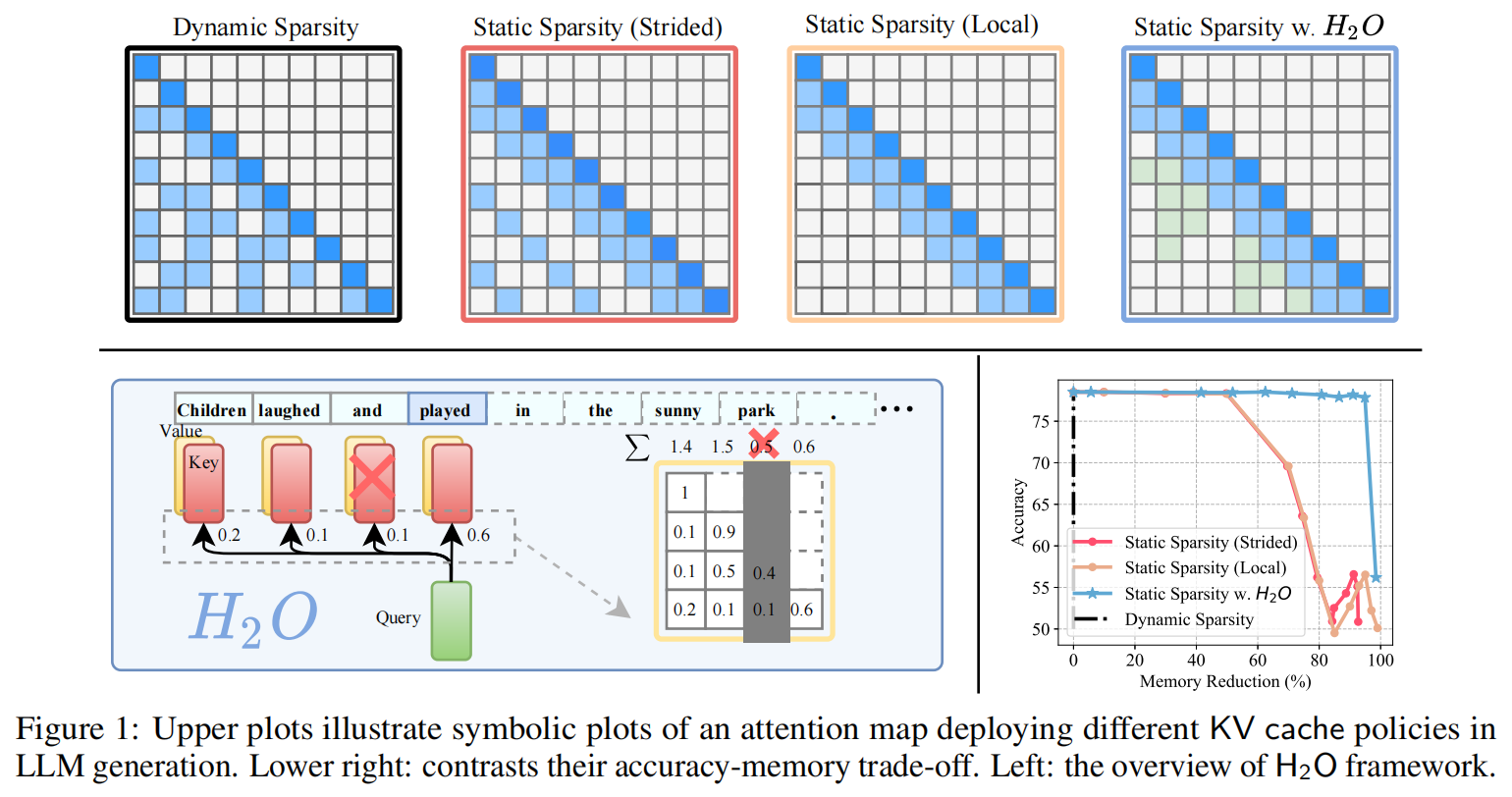
可以看到,Overview里主要对比了下面三种方法:
- 动态稀疏 (Dynamic Sparsity):不拘泥于固定的位置或距离,而是在模型生成每一个词的当下,根据当前的注意力计算情况动态地决定哪些词的历史记忆是有用的,并把它们保留下来。虽然理论上最合适,但在实际代码运行中,想要在极短的时间内精准算出“到底哪些词构成了最优组合”也是一个计算量极其庞大的数学组合问题。
- 步幅稀疏 (Static Sparsity - Strided):按照固定的间隔(比如每隔 2 个词或 3 个词)保留记忆,这是一种类似于网格的固定规则。然而语言的信息分布是不均匀的。一个关键的动词或名词大概率不会刚好落在你设定的固定间隔点上。
- 局部稀疏 (Static Sparsity - Local):只保留距离当前位置最近的几个词(Token)的记忆,强制丢弃所有更早之前的词,就像一个滑动窗口永远只关注紧挨着当前位置的上下文。如果一篇文章的关键信息在上下文更早的地方,局部稀疏就会因为丢失长程上下文而导致生成内容前后矛盾
而论文提出的算法,实际上就是一种极其讨巧且低成本的“动态稀疏” 。作者发现不需要做复杂的数学组合计算,只需要把历史上得分一直很高的Heavy-Hitters挑出来,再结合最近的几个词组合在一起,就能完美模拟出动态稀疏的效果。
2 H2O方法设计
2.1 Observation
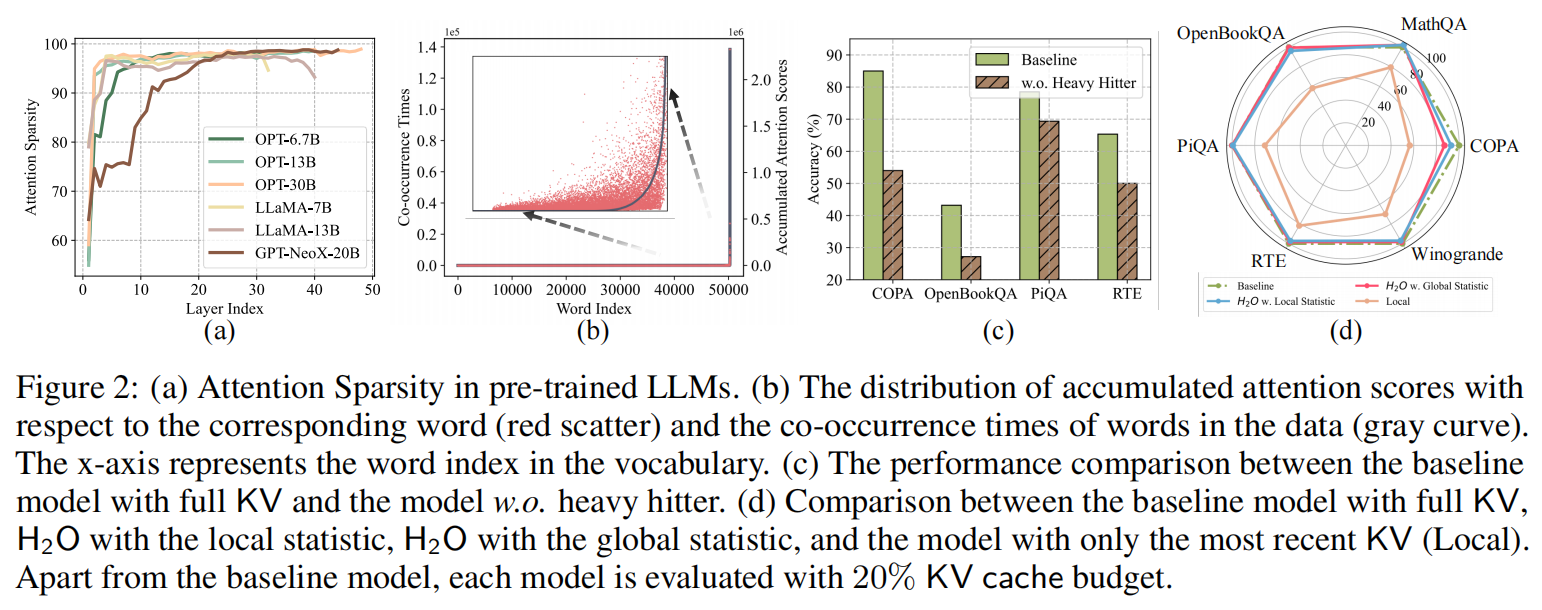
2.1.1 注意力的极度稀疏性
作者首先进行了这样一个实验,模型在推理时,会通过查询矩阵 和键矩阵 计算出标准的归一化注意力得分矩阵,即 。(论文为了方便写成了),然后在注意力矩阵的每一行中,他们首先找出该行的最大注意力得分,然后将阈值设定为这个最大值的 1% 。在同一行中,任何低于这个“最大值 1%”阈值的注意力得分,都会被视作稀疏的注意力。统计这些低于阈值的元素所占的比例,就得出了该层的“稀疏度” 。
如上图(a), 作者用预训练好的大模型都跑了一遍测试,发现了一个惊人的事实——尽管大模型在训练时是密集的,但在实际推理生成文本时,它的注意力得分矩阵超过 95% 都是稀疏的(即得分极其微小,趋近于 0)。这意味着模型在预测下一个词时,根本不需要回头看之前生成的所有词的 KV 缓存。大部分历史词的缓存对当前的生成是无效的。因此直接扔掉它们理论上可以把 KV Cache 缩小将近 20 倍,且不会掉准确率。
2.1.2 Heavy-Hitter现象
接下来,作者让预训练大模型运行文本生成任务并针对词汇表中的每一个单词统计了两个完全独立的数据:
- 指标一:累积注意力得分(Accumulated Attention Scores)。在模型推理时,统计某个词在所有的注意力块中被其他词汇分配到的注意力分数总和 。这代表了模型在内部计算时对这个词的依赖程度。
- 指标二:数据共现次数(Co-occurrence Times)。作者还统计了这些词在真实的外部语料数据中,与其他词语共同出现的频率 。这个的统计方法具体怎么做文中没有写,但是一般都是构建一个共现矩阵,大小为语料库乘语料库大小,然后用一个滑动窗口扫描整个语料。比如如果在某个窗口内,单词 (比如 “apple”)和单词 (比如 “eat”)同时出现了,那么矩阵中的 的计数就会加 1。扫完全部语料后,这个矩阵就记录了所有词汇两两之间的搭配频率。
最后结果如上图(b),横轴的word Index是重新排序后的结果。作者发现,大模型分配给历史 Token 的注意力总分呈现幂律分布。也就是说,存在极少数的几个词,它们吸走了绝大多数的注意力分数。作者把这些极为关键的词称为 Heavy-Hitters()。另外如上图©,作者做了一个破坏性试验——如果把这些 词的KV cache故意删掉,大模型的生成质量会大幅度降低(注意 KV cache是不是备份性的缓存,而是唯一的记忆内容,没了就是没了);相反,如上图(d),如果只保留 和最近生成的几个词(Local Token),大模型的表现几乎和保留全量缓存一模一样。
2.2 方法
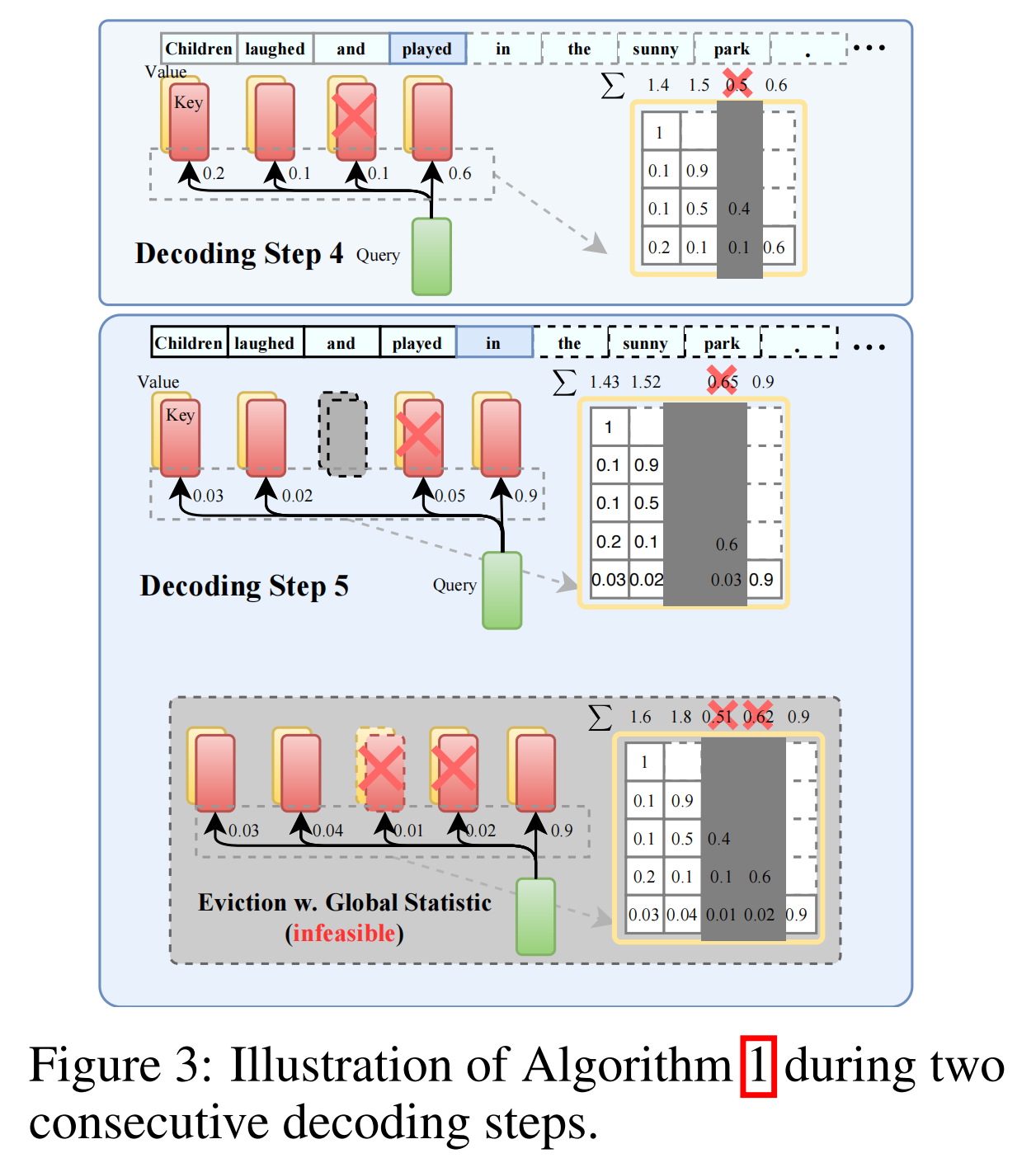
基于上述现象,作者提出了方法,具体过程如下:
- 划定预算:假设系统最多只允许存放 个词的缓存。算法把这 个名额一分为二,一半留给“最近生成的词()”,另一半则全留给“重击者()”。
- 本地记账本(Local Statistic):系统在后台维护一个分数榜单。每生成一个新词,系统就把这个新词对前面所有历史词的注意力分数和历史词的历史注意力分数加起来不断累积。因为只用已经发生的数据,所以计算成本极低。
- 贪心执行:当缓存快被塞满时算法会启动清理机制。它会保住最近刚生成的几个词,然后去查看剩下的历史词的分数榜单,直接把累积得分最低的词从显存中删除。
当缓存预算只有3的时候,总体过程如上图3
2.3 系统实现
在系统实现上,作者提到了一个非常关键的工程细节:内存的高效读写(I/O efficiency)。
- 传统的低效做法:在显存里删掉一个缓存词,然后把后面的词往前挪,这种“显存碎片整理”会极大地拖慢大模型的生成速度。
- 的巧妙做法:不去做复杂的swap memory。当算法决定要淘汰某个旧词的 KV 缓存时,系统干脆直接把那个位置标记为“可用”,然后直接把新生成词的 KV 缓存覆盖(填入)到那个旧词的内存地址上 。
3 实验
3.1 实验设置
3.1.1 baseline与实现
baseline主要选了下面几种:
- Full KV Cache:完整KV缓存,无限制大小
- Local:通过滑动窗口策略仅保留了最近的KV
- Sparse Transformer (Strided):固定间隔稀疏注意力
- Sparse Transformer (Fixed):固定局部窗口稀疏注意力
- Top-K:直接保留注意力当前分数最高的K个token
3.1.2 数据集
总共包括如下数据集:
| 来源 | 具体任务 |
|---|---|
| lm-eval-harness (6个任务) | COPA, MathQA, OpenBookQA, PiQA, RTE, Winogrande |
| HELM (2个任务) | XSUM, CNN/Daily Mail |
| 长序列生成 | AlpacaEval, MT-bench |
测试的模型:
- OPT (6.7B, 13B, 30B, 66B, 175B)
- LLaMA (7B, 13B, 30B)
- GPT-NeoX-20B
3.1.3 评估指标
- 准确率:下游任务准确率
- 内存效率:KV缓存预算比例,这个指标等于实际保留的KV数量 / 原始完整KV数量
- token吞吐量:包含prefill+decoding的端到端生成速度tokens/s
- 推理延迟:答案生成的具体时间
- 文本多样性:主要是用Self-BLEU,越低表示生成越多样
- 长序列能力:测试无限长输入(up to 4M tokens)
3.2 实验结果
3.2.1 主要结果
首先是作者通过测试 4% 到 100% 不同的KV Cache Budget范围和不同数据集不同模型,得出了下面的结果图:
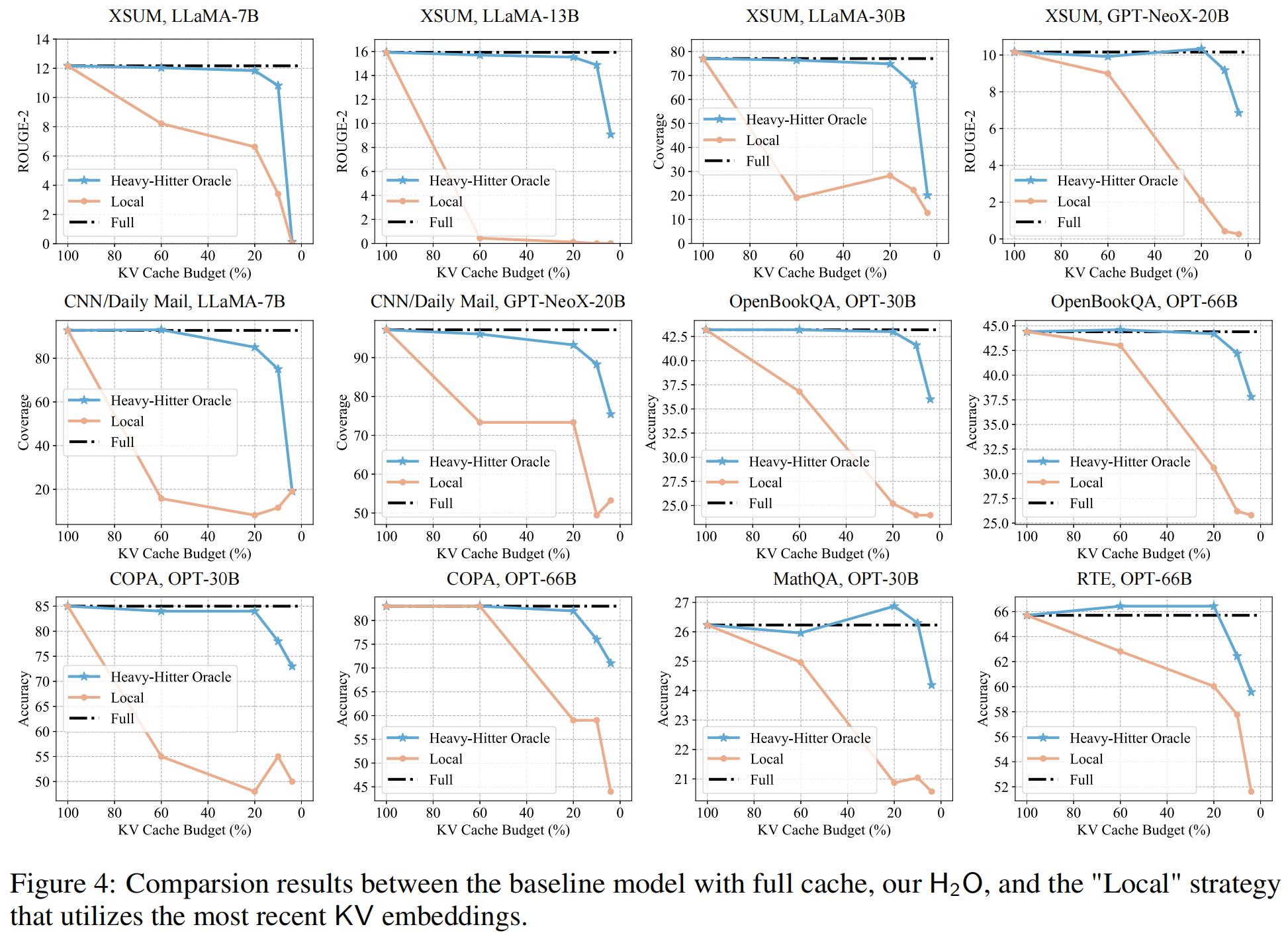
在不同缓存预算下,面对各种模型尺寸和下游任务, 的表现始终且显著地优于“只保留最近词”的 Local 策略,与全cache几乎效果齐平。
接下来,作者做了更大胆的实验,他设计了在20% KV Cache预算的情况下, 依然成功取得了与使用 100% 全量 KV 嵌入的模型相当的性能,具体如下表:
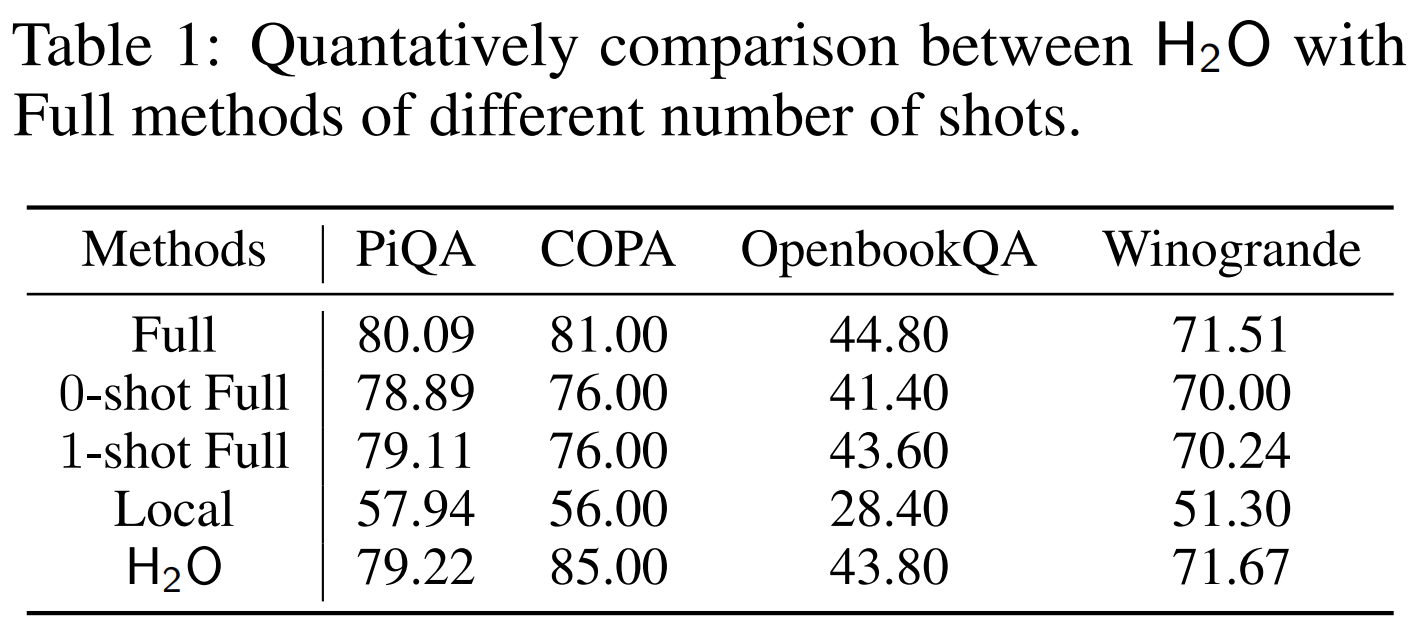
另外,他还尝试了在20% KV Cache预算的情况下,用插入到其他的一些压缩算法中,证明了现象是自然语言的底层规律,它可以作为万能插件拯救各种老旧的压缩算法。
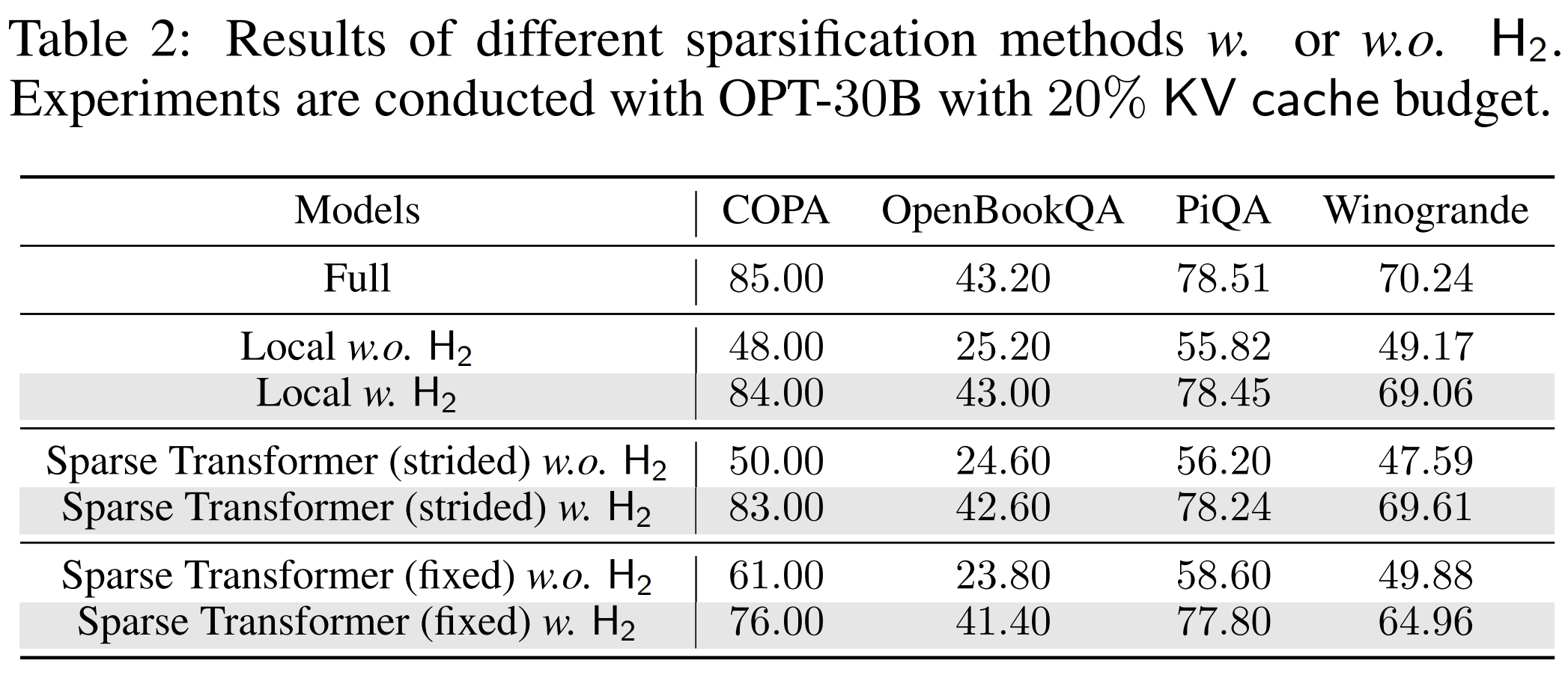
3.2.2 效率实验
当 KV Cache 太大显存装不下时,系统只能先把数据转移到缓慢的系统内存(CPU)里,这叫 Offloading。这样极其拖慢速度。 将缓存压缩到 20%,使得很多原本需要卸载到 CPU 的任务,现在可以在 GPU 显存里直接计算,所以速度会变得更快。
作者首先使用的是人工合成的、极其规整的数据。所有的prompt都被强行Padding到了完全相同的固定长度,并且系统被要求为每个提示词生成完全相同数量的Tokens。如下表,可以在表头看到非常明确且固定的长度组合指标,例如 512+32(输入 512 词,要求生成 32 词)、512+512 或 512+1024:
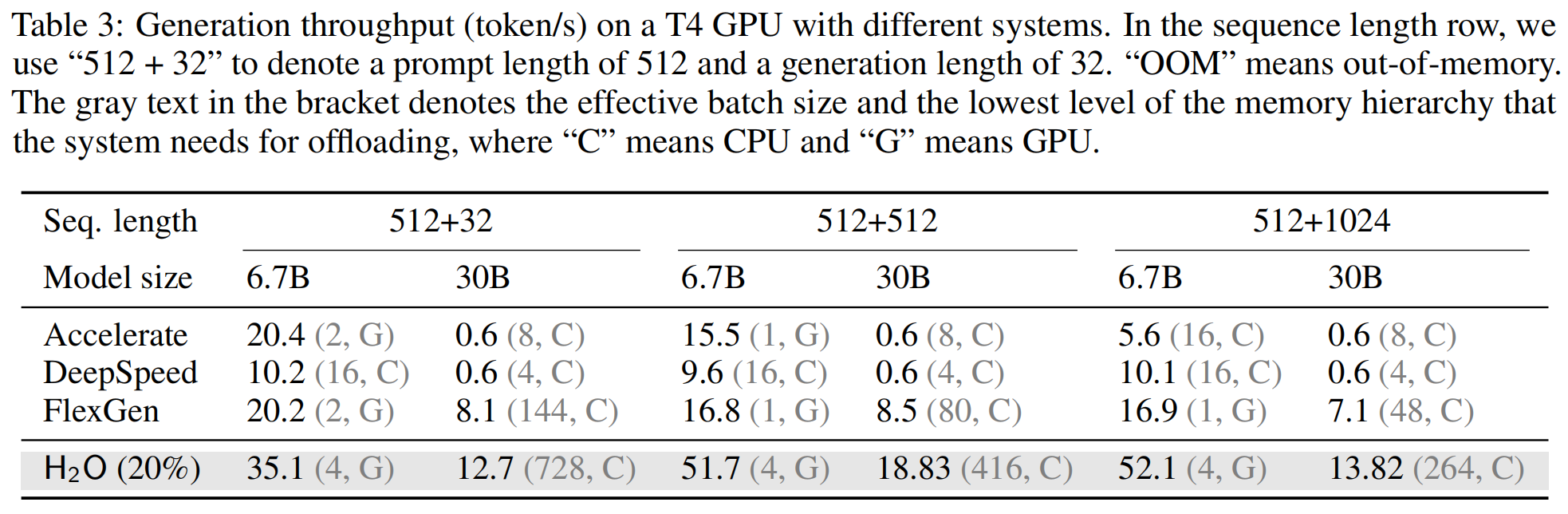
接下来,作者换用了 XSUM 数据集(一个被广泛使用的真实新闻文本摘要数据集)进行进一步的评估。在真实的摘要任务中,每一篇新闻的长度是不一样的,模型总结出来的句子长短也是自然波动的:

最后,作者又换回了人工合成的数据集,并从T4(16GB 显存)换到A100(80GB 显存)上,证明 能够驾驭超长文本:

3.3 消融实验
这里实验做的很多,就不一个个贴了,主要记一下几个问答:
Q1: 能否让模型处理“无限长度”的输入
可以,最高能撑到 400 万个 Token(词元)。之前业界有一种叫 StreamLLM 的技术专门做长文本流式生成。作者把 拿去和 StreamLLM 对比,发现 在各种缓存大小下的表现(困惑度指标)都优于 StreamLLM,成功实现了长达 400 万词元的有效流式生成,打破了模型原本的长度限制。
Q2:提示词里示例的数量(Few-shot)会影响 的效果吗?
不受影响,从 0-shot 到 10-shot 都极其稳定。 无论给不给模型举任何例子, 都能在仅用 20% 内存预算的情况下,保持与 100% 满血全量缓存模型几乎一模一样的准确率。这证明了算法在不同任务难度和长度下都具备极强的鲁棒性。
Q3: 能和量化技术一起用吗?
完美兼容,甚至强强联合效果更好。 直觉上,既删缓存又压精度,误差可能会叠加导致模型崩溃。然而实验证明两者结合后,准确率甚至经常比单独使用 或单独使用量化还要高一点点。
Q4: 到底为什么能追平满血模型?
和Local tokens缺一不可。 作者分别测试了“只留重击者”和“只留最近词”。结果发现,单独用哪一个都会导致模型掉点(性能下降幅度在 2.85% 到 22.75% 之间)。只有把这两者结合起来(也就是完整的 策略),才能真正复刻满血缓存的实力。另外,数据还表明对维持模型性能的贡献要比最近词更大。
Q5: 还有什么额外好处吗?
意外提高了生成文本的多样性。 以前大模型在生成长文章时,经常容易变成复读机。而采用 策略后,因为系统强行扔掉了大量无用的历史冗余缓存,模型反而摆脱了之前说过的话的束缚。生成的句子重复词汇更少,展现出了更高的创造力和多样性。
4 总结与感想
H2O这篇论文其实整体思想和memory的思想很像的,就是KV Cache的长期记忆(Heavy-Hitter)+ 短期记忆(local tokens),同时这篇论文其实也提醒我们连词的重要性比我们想的要更多,因为连词的出现频率高,很有可能累积注意力成Heavy-Hitter,也就是说注意力高的词可能和语义关系并不大。无独有偶,StreamingLLM[2]这篇论文里也发现Attention分布会牢牢锁在一些固定的词上,即使这个词没有什么语义(比如The)。
另外,还有个值得讨论的点,在CoT时代,思考的attention和answer的attention分布是否是相似的?如果是相似的(比如都聚焦在query中),是否可以说answer其实并没有关注思考过程?而如果不相似(比如answer注意力更多集中在思考上),是否可以把query的一些KV cache消除掉?这个也算是高效推理的一个idea了。
Zhang Z, Sheng Y, Zhou T, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models[J]. Advances in Neural Information Processing Systems, 2023, 36: 34661-34710. ↩︎
Xiao G, Tian Y, Chen B, et al. Efficient streaming language models with attention sinks[C]//International Conference on Learning Representations. 2024, 2024: 21875-21895. ↩︎



