本文梳理 KV Cache 压缩从标准多头注意力(MHA),经 MQA、GQA、MLA(DeepSeek-V2),一路演进到 DeepSeek-V4 的 CSA+HCA 混合架构的完整脉络。
1 起点:MHA 与 KV Cache 困境
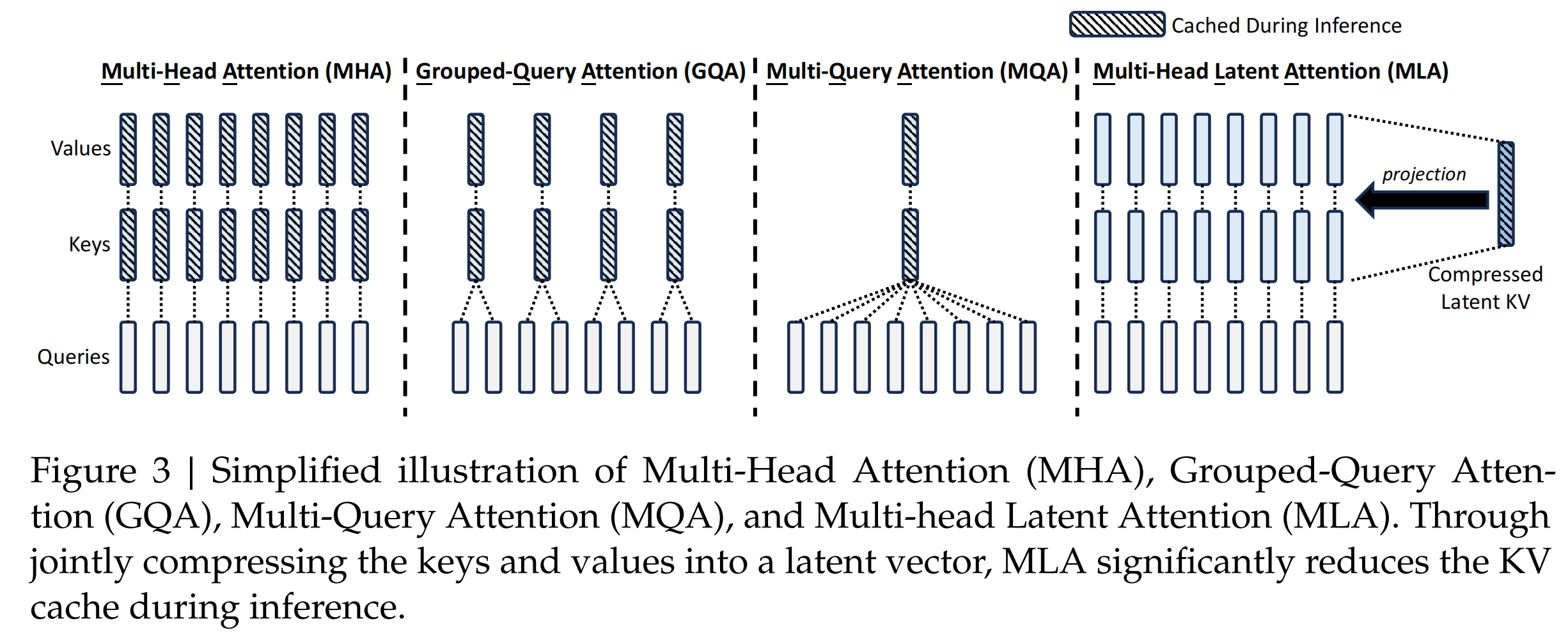
1.1 什么是 MHA(Multi-Head Attention,多头注意力)
标准 Transformer 的注意力层由多个注意力头组成,每个头独立地对输入做 Query (Q Q Q K K K V V V
其中的单头注意力 :
head i = Attention ( Q i , K i , V i ) = softmax ( Q i K i T d k ) V i \text{head}_i = \text{Attention}(Q_i, K_i, V_i) = \text{softmax}\left(\frac{Q_i K_i^T}{\sqrt{d_k}}\right) V_i
head i = Attention ( Q i , K i , V i ) = softmax ( d k Q i K i T ) V i
其中 Q i = X W i Q Q_i = X W_i^Q Q i = X W i Q K i = X W i K K_i = X W_i^K K i = X W i K V i = X W i V V_i = X W_i^V V i = X W i V W i Q , W i K ∈ R d × d k W_i^Q, W_i^K \in \mathbb{R}^{d \times d_k} W i Q , W i K ∈ R d × d k W i V ∈ R d × d v W_i^V \in \mathbb{R}^{d \times d_v} W i V ∈ R d × d v
多头拼接 :
MHA ( X ) = Concat ( head 1 , … , head h ) W O \text{MHA}(X) = \text{Concat}(\text{head}_1, \dots, \text{head}_h) W^O
MHA ( X ) = Concat ( head 1 , … , head h ) W O
其中 W O ∈ R h d v × d W^O \in \mathbb{R}^{h d_v \times d} W O ∈ R h d v × d
自回归解码时,每个头生成的 K i K_i K i V i V_i V i L L L h h h K K K d k d_k d k V V V d v d_v d v d k = d v d_k = d_v d k = d v n n n
KV Cache 大小 = L × h × ( d k + d v ) × n \text{KV Cache 大小} = L \times h \times (d_k + d_v) \times n
KV Cache 大小 = L × h × ( d k + d v ) × n
其中 n n n 线性增长 ——序列翻倍,缓存也翻倍。
1.2 为什么 KV Cache 是瓶颈?
把公式展开看就清楚了。取 LLaMA-2 70B 的实际参数(L = 80 L=80 L = 80 h = 64 h=64 h = 64 d k = d v = 128 d_k = d_v = 128 d k = d v = 128 n = 128 K n=128K n = 128 K
KV Cache = 80 × 64 × ( 128 + 128 ) × 128 × 10 3 × 2 bytes ≈ 167 GB \text{KV Cache} = 80 \times 64 \times (128 + 128) \times 128 \times 10^3 \times 2 \text{ bytes} \approx 167 \text{ GB}
KV Cache = 80 × 64 × ( 128 + 128 ) × 128 × 1 0 3 × 2 bytes ≈ 167 GB
作为对比,LLaMA-2 70B 参数总量约 70B 个浮点数,FP16 下每个参数占 2 bytes:
70 × 10 9 × 2 bytes = 140 GB 70 \times 10^9 \times 2 \text{ bytes} = 140 \text{ GB}
70 × 1 0 9 × 2 bytes = 140 GB
也就是说,处理 128K 上下文时,缓存比模型还大 ——光是给推理过程中缓存"对话记忆"的显存开销,已经超过了模型全部权重本身。
由此引出 KV Cache 公式中每一项的含义和可压缩性:
KV Cache = L ⏟ 层 × h ⏟ 头 × ( d k + d v ) ⏟ 维度 × n \text{KV Cache} = \underbrace{L}_{\text{层}} \times \underbrace{h}_{\text{头}} \times \underbrace{(d_k + d_v)}_{\text{维度}} \times n
KV Cache = 层 L × 头 h × 维度 ( d k + d v ) × n
后续的技术正是沿着这三个乘数因子逐一削减:
h h h g g g 头间共享 ( d k + d v ) (d_k + d_v) ( d k + d v ) K , V K, V K , V 维度压缩 n n n 序列稀疏
2 共享注意力头——MQA 与 GQA
事实上,所有注意力头的K K K V V V h h h K K K V V V
2.1 MQA(Multi-Query Attention,多查询注意力)
2019 年,Shazeer 提出(顺便提一嘴,这篇是独立作者,还挺厉害的):所有头共享同一组 K , V K, V K , V Q Q Q
Q i = X W i Q , K = X W K , V = X W V Q_i = X W_i^Q, \quad K = X W^K, \quad V = X W^V
Q i = X W i Q , K = X W K , V = X W V
head i = softmax ( Q i K T d k ) V \text{head}_i = \text{softmax}\left(\frac{Q_i K^T}{\sqrt{d_k}}\right) V
head i = softmax ( d k Q i K T ) V
MHA 的 KV Cache = L × h × ( d k + d v ) × n \text{MHA 的 KV Cache} = L \times h \times (d_k + d_v) \times n
MHA 的 KV Cache = L × h × ( d k + d v ) × n
MQA 的 KV Cache = L × 1 × ( d k + d v ) × n = 1 h × MHA 的 KV Cache \text{MQA 的 KV Cache} = L \times 1 \times (d_k + d_v) \times n = \frac{1}{h} \times \text{MHA 的 KV Cache}
MQA 的 KV Cache = L × 1 × ( d k + d v ) × n = h 1 × MHA 的 KV Cache
h = 64 h=64 h = 64 Q Q Q K K K V V V K K K V V V
2.2 GQA(Grouped-Query Attention,分组查询注意力)
2023 年,GQA 提出了一个自然的折中方法:把 h h h g g g K , V K, V K , V j j j { h ( j − 1 ) g + 1 , … , h j g } \{h_{(j-1)g+1}, \dots, h_{jg}\} { h ( j − 1 ) g + 1 , … , h j g }
K ( j ) = X W ( j ) K , V ( j ) = X W ( j ) V , j ∈ { 1 , … , g } K^{(j)} = X W_{(j)}^K, \quad V^{(j)} = X W_{(j)}^V, \quad j \in \{1, \dots, g\}
K ( j ) = X W ( j ) K , V ( j ) = X W ( j ) V , j ∈ { 1 , … , g }
每个头的 Q i Q_i Q i K K K V V V
head i = softmax ( Q i ( K ( j ) ) T d k ) V ( j ) \text{head}_i = \text{softmax}\left(\frac{Q_i (K^{(j)})^T}{\sqrt{d_k}}\right) V^{(j)}
head i = softmax ( d k Q i ( K ( j ) ) T ) V ( j )
GQA 的 KV Cache = L × g × ( d k + d v ) × n = g h × MHA 的 KV Cache \text{GQA 的 KV Cache} = L \times g \times (d_k + d_v) \times n = \frac{g}{h} \times \text{MHA 的 KV Cache}
GQA 的 KV Cache = L × g × ( d k + d v ) × n = h g × MHA 的 KV Cache
g = 1 g=1 g = 1 g = h g=h g = h 实践中 g = 8 g=8 g = 8
GQA 的核心想法 :不需要每个头都存一份 K , V K, V K , V
3 压缩隐藏层维度——MLA
GQA 在"头"维度上做了共享,但每个 token 仍需存储完整的 K , V K, V K , V K , V K, V K , V
3.1 MLA(Multi-head Latent Attention,多头潜在注意力)
MLA 来自 DeepSeek-V2,其核心思想是:与其为 h h h K , V K, V K , V
3.1.1 为什么所有头共享一个潜在向量?
关键观察是秩。在标准 MHA 中,每个头的 K K K h t ∈ R d h_t \in \mathbb{R}^d h t ∈ R d d d d W i K ∈ R d k × d W_i^K \in \mathbb{R}^{d_k \times d} W i K ∈ R d k × d
K 1 = W 1 K h t , K 2 = W 2 K h t , … , K h = W h K h t K_1 = W_1^K h_t,\; K_2 = W_2^K h_t,\; \dots,\; K_h = W_h^K h_t
K 1 = W 1 K h t , K 2 = W 2 K h t , … , K h = W h K h t
把 h h h K K K
[ K 1 K 2 ⋮ K h ] = [ W 1 K W 2 K ⋮ W h K ] ⏟ W K ∈ R h d k × d ⋅ h t \begin{bmatrix} K_1 \\ K_2 \\ \vdots \\ K_h \end{bmatrix} = \underbrace{\begin{bmatrix} W_1^K \\ W_2^K \\ \vdots \\ W_h^K \end{bmatrix}}_{\mathbf{W}^K\; \in\; \mathbb{R}^{h d_k \times d}} \cdot \; h_t
K 1 K 2 ⋮ K h = W K ∈ R h d k × d W 1 K W 2 K ⋮ W h K ⋅ h t
堆叠矩阵 W K \mathbf{W}^K W K h d k h d_k h d k d d d rank ( W K ) ≤ min ( h d k , d ) \text{rank}(\mathbf{W}^K) \le \min(h d_k, d) rank ( W K ) ≤ min ( h d k , d ) d k = d / h d_k = d/h d k = d / h h d k = d h d_k = d h d k = d d d d d = 5120 d=5120 d = 5120 h = 128 h=128 h = 128 d k = 128 d_k=128 d k = 128 h d k = 16384 ≫ 5120 = d h d_k = 16384 \gg 5120 = d h d k = 16384 ≫ 5120 = d d = 5120 d=5120 d = 5120 16384 − 5120 = 11264 16384 - 5120 = 11264 16384 − 5120 = 11264
3.1.2 具体流程
MLA 的思路如下:不存 h d k h d_k h d k d c d_c d c c t K V c_t^{KV} c t K V W i U K ∈ R d c × d k W_i^{UK} \in \mathbb{R}^{d_c \times d_k} W i U K ∈ R d c × d k K K K V V V
(1)压缩 :用降维矩阵 W D K V ∈ R d × d c W^{DKV} \in \mathbb{R}^{d \times d_c} W D K V ∈ R d × d c h t h_t h t
c t K V = W D K V h t ∈ R d c c_t^{KV} = W^{DKV} h_t \in \mathbb{R}^{d_c}
c t K V = W D K V h t ∈ R d c
其中 d c d_c d c h × d k h \times d_k h × d k d c = 512 d_c=512 d c = 512 h × d k = 128 × 128 = 16384 h \times d_k = 128 \times 128 = 16384 h × d k = 128 × 128 = 16384
(2)缓存 :只存 c t K V c_t^{KV} c t K V K , V K, V K , V h × ( d k + d v ) h \times (d_k+d_v) h × ( d k + d v ) d c d_c d c
(3)恢复 :每个头用自己专属的升维矩阵从 c t K V c_t^{KV} c t K V K K K V V V
k t , i C = W i U K c t K V , v t , i = W i U V c t K V k_{t,i}^{\text{C}} = W_i^{UK} c_t^{KV}, \quad v_{t,i} = W_i^{UV} c_t^{KV}
k t , i C = W i U K c t K V , v t , i = W i U V c t K V
其中 W i U K ∈ R d c × d k W_i^{UK} \in \mathbb{R}^{d_c \times d_k} W i U K ∈ R d c × d k W i U V ∈ R d c × d v W_i^{UV} \in \mathbb{R}^{d_c \times d_v} W i U V ∈ R d c × d v
注:Q Q Q (c t Q = W D Q h t c_t^Q = W^{DQ} h_t c t Q = W D Q h t q t , i = W i U Q c t Q q_{t,i} = W_i^{UQ} c_t^Q q t , i = W i U Q c t Q Q Q Q K , V K, V K , V
3.1.3 旋转位置编码的解耦
在前面我们已经介绍了MLA的基本想法,但是有一个问题,就是Rope位置编码。注意力计算时候的K K K K K K K K K K K K K K K 但是我们的W i U K W_i^{UK} W i U K c t K V c_t^{KV} c t K V W i U K W_i^{UK} W i U K 。但是我们又不可能对恢复的K K K K K K
DeepSeek-V2 的解法是解耦 RoPE(Decoupled RoPE) 。每个 token 缓存下述两样东西 :
内容向量 c t K V ∈ R d c c_t^{KV} \in \mathbb{R}^{d_c} c t K V ∈ R d c d c = 512 d_c=512 d c = 512 位置分量 r t , i ∈ R d r r_{t,i} \in \mathbb{R}^{d_r} r t , i ∈ R d r d r = 64 d_r=64 d r = 64 h t h_t h t r t , i = RoPE t ( W i K R h t ) r_{t,i} = \text{RoPE}_t(W_i^{KR} h_t) r t , i = RoPE t ( W i K R h t ) W i K R ∈ R d × d r W_i^{KR} \in \mathbb{R}^{d \times d_r} W i K R ∈ R d × d r t t t W i K R W_i^{KR} W i K R
解码时,每个头把内容部分和位置部分拼接 成完整的 K K K
k t , i = [ W i U K c t K V ⏟ 从共享缓存展开, 128维 ; r t , i ⏟ 从按头缓存读取, 64维 ] ∈ R d k + d r k_{t,i} = \big[\,\underbrace{W_i^{UK} c_t^{KV}}_{\text{从共享缓存展开, 128维}} \;\;;\;\; \underbrace{r_{t,i}}_{\text{从按头缓存读取, 64维}}\,\big] \in \mathbb{R}^{d_k + d_r}
k t , i = [ 从共享缓存展开 , 128 维 W i U K c t K V ; 从按头缓存读取 , 64 维 r t , i ] ∈ R d k + d r
这样最后即保留了内容信息,又保留了位置信息,总计缓存d c + h ⋅ d r = 512 + 128 × 64 = 8704 d_c + h \cdot d_r = 512 + 128 \times 64 = 8704 d c + h ⋅ d r = 512 + 128 × 64 = 8704 32768 32768 32768 26.6 % 26.6\% 26.6%
Q Q Q V V V
4 压缩token序列
MLA 把每个 token 的 K , V K, V K , V 每一个 token 分配同等预算。而现实中,序列里大部分 token 对当前生成几乎无影响——真正相关的可能只有几百个。与其 100 万 token 全存,不如只挑最重要的。
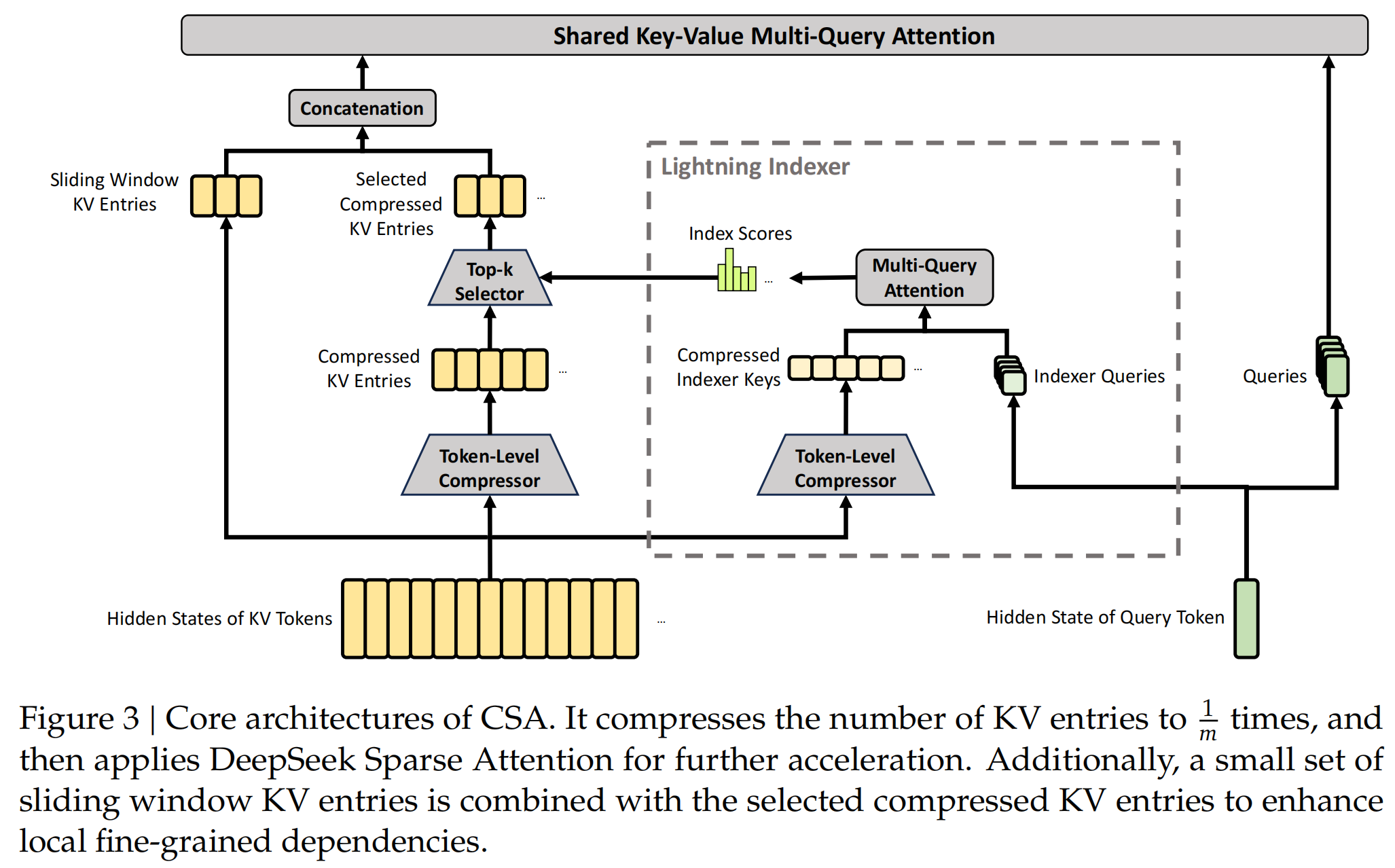
4.1 CSA(Compressed Sparse Attention,压缩稀疏注意力)
CSA(Compressed Sparse Attention,压缩稀疏注意力)来自 DeepSeek-V4,其主要内容分三步:压缩 、稀疏选择 、滑动窗口 。
4.1.1 压缩
每 m m m n n n n / m n/m n / m
关键设计是带重叠的压缩 :每个压缩条目不止看自己的 m m m m m m 2 m 2m 2 m
[ S m i : m ( i + 1 ) − 1 a ; S m ( i − 1 ) : m i − 1 b ] = Softmax row ( [ Z m i : m ( i + 1 ) − 1 a + B a ; Z m ( i − 1 ) : m i − 1 b + B b ] ) [S_{mi:m(i+1)-1}^a; S_{m(i-1):mi-1}^b] = \text{Softmax}_{\text{row}}([Z_{mi:m(i+1)-1}^a + B^a; Z_{m(i-1):mi-1}^b + B^b])
[ S mi : m ( i + 1 ) − 1 a ; S m ( i − 1 ) : mi − 1 b ] = Softmax row ([ Z mi : m ( i + 1 ) − 1 a + B a ; Z m ( i − 1 ) : mi − 1 b + B b ])
C i Comp = ∑ j = m i m ( i + 1 ) − 1 S j a ⊙ C j a + ∑ j = m ( i − 1 ) m i − 1 S j b ⊙ C j b C_i^{\text{Comp}} = \sum_{j=mi}^{m(i+1)-1} S_j^a \odot C_j^a + \sum_{j=m(i-1)}^{mi-1} S_j^b \odot C_j^b
C i Comp = j = mi ∑ m ( i + 1 ) − 1 S j a ⊙ C j a + j = m ( i − 1 ) ∑ mi − 1 S j b ⊙ C j b
其中 C a , C b C^a, C^b C a , C b C a C^a C a C b C^b C b Z a , Z b Z^a, Z^b Z a , Z b B a , B b B^a, B^b B a , B b ⊙ \odot ⊙
4.1.2 稀疏选择
压缩后还有 n / m n/m n / m Lightning Indexer 先用一个低秩投影把 query 和压缩块 Key 都降到低维,快速打分。ReLU 清零负得分(无关块直接淘汰),剩下按分数取 Top-k k k
I t , s = ∑ h = 1 n h I w t , h I ⋅ ReLU ( q t , h I ⋅ k s IComp ) I_{t,s} = \sum_{h=1}^{n_h^I} w_{t,h}^I \cdot \text{ReLU}(q_{t,h}^I \cdot k_s^{\text{IComp}})
I t , s = h = 1 ∑ n h I w t , h I ⋅ ReLU ( q t , h I ⋅ k s IComp )
C t SprsComp = { C s Comp ∣ I t , s ∈ Top- k ( I t , : ) } C_t^{\text{SprsComp}} = \{C_s^{\text{Comp}} \mid I_{t,s} \in \text{Top-}k(I_{t,:})\}
C t SprsComp = { C s Comp ∣ I t , s ∈ Top- k ( I t , : )}
其中 q t , h I q_{t,h}^I q t , h I k s IComp k_s^{\text{IComp}} k s IComp w t , h I w_{t,h}^I w t , h I
4.1.3 滑动窗口
如果完全按照上述attention压缩方法,当前 token 看不到自己所在块内的相邻 token,会导致局部信息有盲区。论文的解决方法是额外保留最近 n win n_{\text{win}} n win 未压缩 KV,与稀疏选出的 k k k
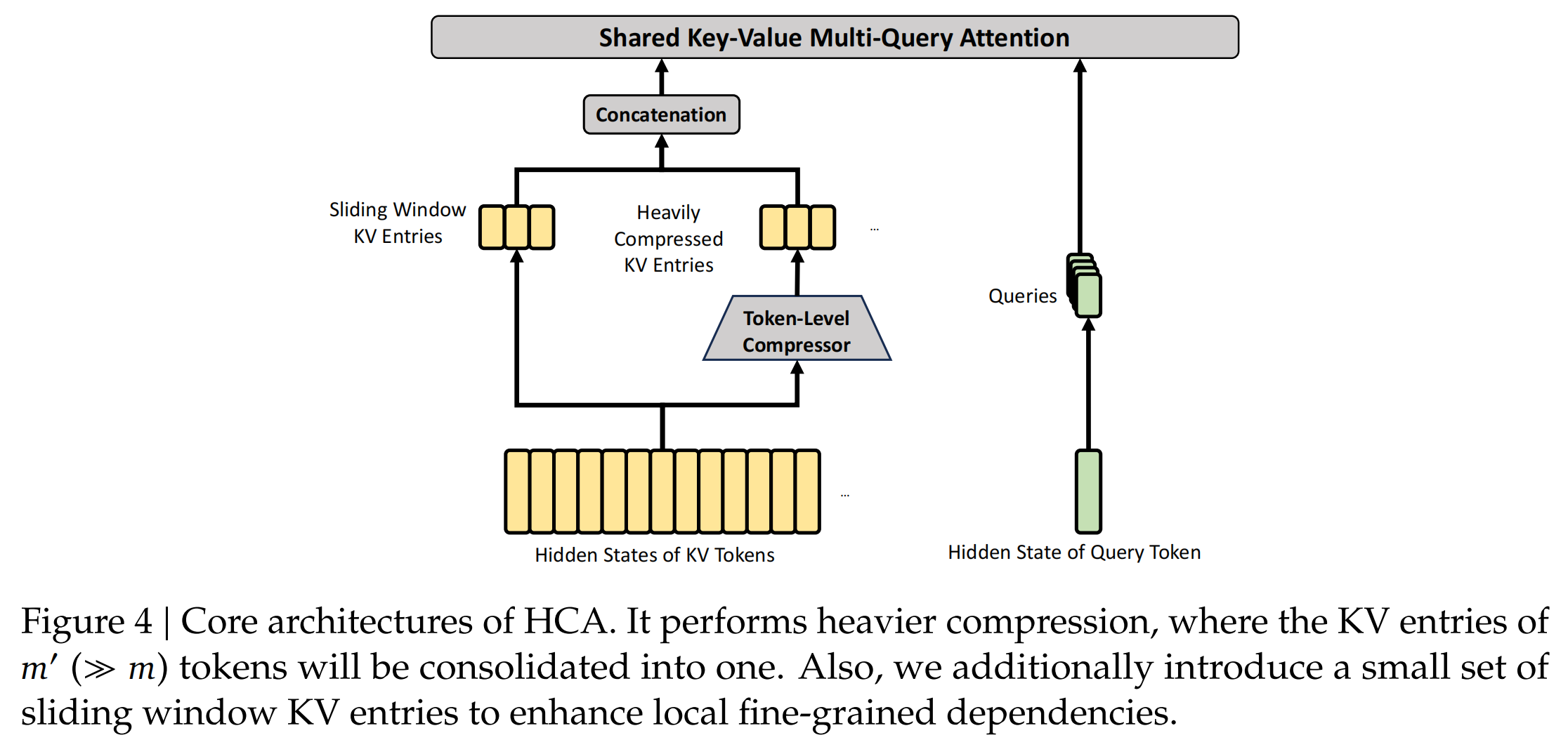
4.2 HCA(Heavily Compressed Attention,重度压缩注意力)
HCA与 CSA 采用相同的软加权压缩,但有下述三个关键区别:
压缩比极大 :m ′ = 128 m'=128 m ′ = 128 n / 128 n/128 n /128 不做稀疏选择 :序列已足够短,直接对所有压缩条目做密集 MQA,压缩条目同时充当 Key 和 Value。与 CSA 交替排布 :61 层中 CSA/HCA 交替(层 0-1 为 HCA),每层只走一个分支。
如果CSA 是压缩后检索重要片段,那HCA就是极度压缩后全局粗读。
5 总结与感想
Attention压缩的每一步,其主要目的都是支持更多的上下文。从压缩头,到压缩向量维度甚至于说压缩token序列。我们发现KV Cache的冗余其实真的很多,尤其是最后的CSA+HCA对token的压缩,几乎完美印证了之前研究里提到的大部分token都是稀疏的想法。这个CSA,某种意义上就是我们之前提到的H2O的做法,即只留下H2和Local Token来削减我们的KV Cache。稀疏注意力的方法现在也是越来越火了,后面可以多关注多模态模型的KV Cache压缩是否和文本模型的KV Cache有不同解法 。