
Efficient LVLM Inference blog
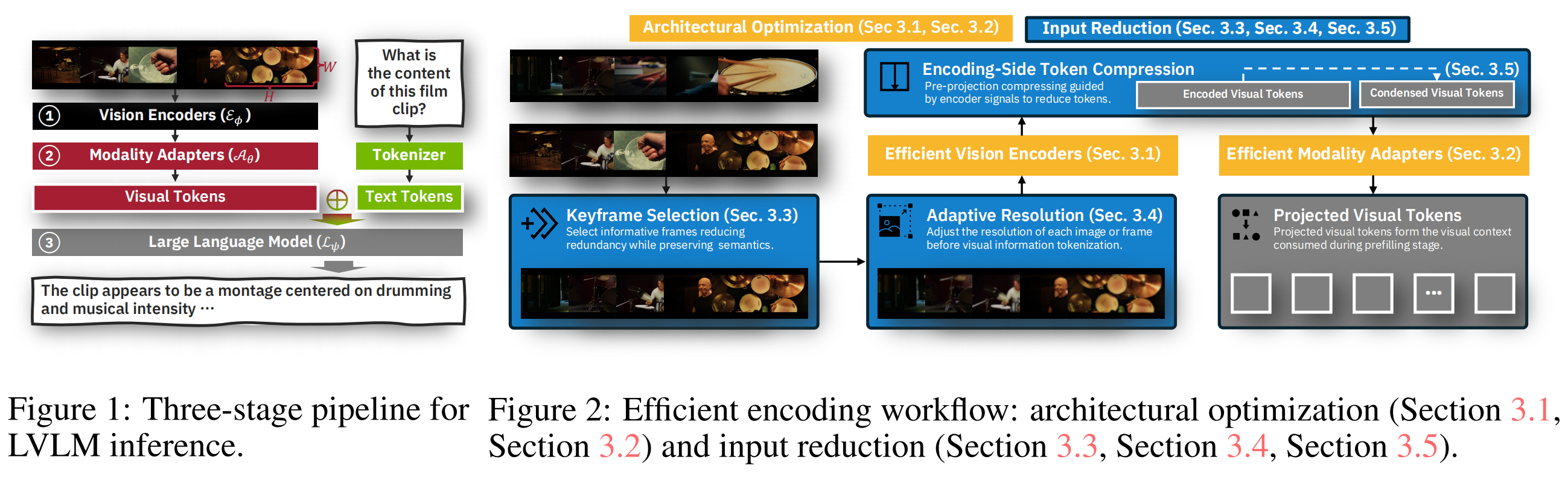
本文内容主要参考综述 [1],该综述将 LVLM 的推理流程划分为三个阶段:编码(Encode)、预填充(Prefill) 和 解码(Decode),并围绕这三个阶段梳理了现有的高效推理技术。
1 第一阶段:编码(Encode)
核心目标:在源头减少视觉 Token 的数量,减轻下游负担。
1.1 架构优化
| 方向 | 思路 |
|---|---|
| 高效视觉编码器 | 改进 Encoder 架构本身 |
| 高效模态适配器 | 改进适配器架构(如 QFormer 相比 MLP 也是一种改良) |
1.2 输入缩减
1.2.1 关键帧选择
主要针对视频,筛选最重要的帧。
1.2.2 自适应分辨率
根据样本的语义难度动态调整分辨率——简单图用低分辨率,复杂图用高分辨率。
1.2.3 编码端 Token 压缩
完全依赖图像固有的空间属性,不依赖文本提示或 LLM 权重 [1:1]。分为两种思路:
- 无视注意力:利用视觉区块天然的空间冗余,用简单的相似度指标合并或修剪冗余特征。
- 利用自注意力:直接利用视觉编码器内部的自注意力机制——如果编码器自己对某些特征没分配太多注意力,说明它们不重要,直接扔掉,保留高价值 Token。
2 第二阶段:预填充(Prefill)
这一阶段发生在编码完成但尚未进入 LLM 深层之前,在 LLM 内部潜在空间里进行压缩。与编码端 Token 压缩类似,也分是否依赖注意力:
2.1 不依赖注意力
通过聚类算法或计算几何距离,把语义重复、长得像的 Token 合并掉。
2.2 依赖注意力
直接拿 LLM 内部的自注意力权重作参考,采用 Early-Exit 策略——在浅层就把注意力得分低的 Token 淘汰掉,节省后续几十层的计算量。
3 第三阶段:解码(Decode)
3.1 KV Cache 压缩
预填充阶段 VLM 压缩幅度相对较小,而解码阶段随着新文本逐步生成,VLM 关注的图像区域会进一步变化,因此 KV Cache 仍有进一步压缩的空间。
3.2 投机解码(Speculative Decoding)
自回归生成最大的瓶颈是"逐 token 串行输出"。投机解码的核心思路:先用一个小模型(草稿模型,Draft Model)快速"猜"出后面几个词,再交给大模型一次性批量验证
在 VLM 中的特殊挑战与应对:
| 挑战 | 解决方案 |
|---|---|
| 视觉上下文庞大,小模型也会变慢 | 训练 / 蒸馏对视觉处理特别快的轻量草稿模型 |
| 不改动模型本身 | 在小模型工作前大幅修剪视觉 Token,利用 LLM 的语言惯性猜词(如 SpecVLM) |
验证机制的改进空间:当前验证要求 100% 匹配,过于死板。对于视觉描述任务,可以采用"语义感知的宽松验证"进一步提速。
3.3 高效推理
从减少生成词数量的角度提效:
- 难度路由:简单图文问题直接给答案,复杂逻辑题展开深度推理链(走"慢车道")。
- 置信度触发:只有当模型对初步答案缺乏信心时才触发扩展推理链(如 CAR)。
- 步骤级优化(未来方向):不仅在整个问题级别做路由,还在推理链的步骤级别做优化——生成过程中动态修剪掉无用的思考步骤。
4 未来方向
4.1 混合压缩
LVLM 的高效推理在未来一定是多个方向的叠加,因为视觉大模型里不同组件对信息流失的敏感度是完全不同的,应该针对模型不同部分的敏感性来量身定制不同的操作。比如,有的地方用检索(Retrieval),有的地方用剪枝(Pruning),有的地方用量化(Quantization),如此压榨出极致的效率。
4.2 模态感知解码
主要是针对前面提到的投机解码说的idea, 即现在的很多加速策略还是在硬套NLP领域的通用启发式方法,这在多模态里是走不通的。
未来方向:必须解决两个核心缺失:
- 视觉草稿对齐(Visual Draft Alignment):得想办法让轻量级的小模型也能扛得住密集的视觉上下文。
- 宽松验证(Relaxed Verification):和上文的想法一样,即只要小助理猜的意思对,哪怕用词不一样,老板也直接给过。
4.3 向流媒体转变(The Streaming Pivot)
这条主要是针对视频的未来观点,即未来的真实应用场景(比如机器人、实时监控)全都是无限时长的流媒体视频,不可能让模型把几个小时的缓存全记住。作者希望未来从"全局整体处理"全面转向"渐进式状态管理",即未来需要为每个阶段量身定制优化方案:编码阶段搞流式的视觉内存管理(比如滑动窗口的frame管理),预填充阶段搞渐进式的 Token 压缩,解码阶段搞具备局部感知的 KV Cache 压缩(不让携带过多历史,而是只感知最近的)。
4.4 端到端系统协同设计
这段主要是说硬件了,就是必须走向软硬件协同设计(Hardware-Algorithm Co-design),让硬件发展更适配VLM推理
5 总结与感想
作者把MLLM高效推理分为以下三个阶段:
- Encode:在源头砍掉冗余视觉 Token
- Prefill:利用 LLM 内部注意力在浅层淘汰低价值 Token
- Decode:KV Cache 压缩 + 投机解码打破串行 + 按需推理减少输出量
未来方向方面,我觉得4.1是一个较容易做的方向,4.2更吃资源但是也可以做,4.3 4.4就更多是一个展望。
另外,文中提到了很多注意力相关的内容,尤其是在encode和decode阶段,都有说通过注意力来选择对应的token,但是 H2O[2]里提到了attention其实不能作为选择重要token的依据,但是MLLMs know where to look
[3]这篇论文又发现相对注意力其实聚焦于真正的图片内容上,而Seeing but not believing[4]这篇也发现LLM的浅层更关注于文字的语义,深层更关注于图片内容。总而言之,或许对于注意力是否能用在高效推理这个领域上,我们还可以多做研究。
J. Zhang, Y. Ji, F. Ren, Y. Li, B. Zeng, Z. Chen, K. Chen, L. Shou, G. Chen, and H. Li, “Efficient Inference for Large Vision-Language Models: Bottlenecks, Techniques, and Prospects,” arXiv preprint arXiv:2604.05546, 2026. https://arxiv.org/abs/2604.05546 ↩︎ ↩︎
Zhang Z, Sheng Y, Zhou T, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models[J]. Advances in Neural Information Processing Systems, 2023, 36: 34661-34710 ↩︎
Khayatkhoei M, Chhikara P, Ilievski F. Mllms know where to look: Training-free perception of small visual details with multimodal llms[C]//International Conference on Learning Representations. 2025, 2025: 68194-68213. ↩︎
Liu Z, Chen Z, Liu H, et al. Seeing but not believing: Probing the disconnect between visual attention and answer correctness in vlms[J]. arXiv preprint arXiv:2510.17771, 2025. ↩︎


