
ARPO
本文主要参考论文 [1]
1 背景与问题
LLM Agent 的训练和纯文本 LLM 有一个关键区别:Agent 不是一次性输出答案,而是在推理过程中不断地调用工具、接收反馈、再决策。现有的 Agent RL 方法(GRPO、DAPO 等)的做法很简单——把整条"思考→调工具→看结果→再思考→输出"的链条当成一条完整回复,用轨迹级 RL 来优化。这忽略了一个重要现象。
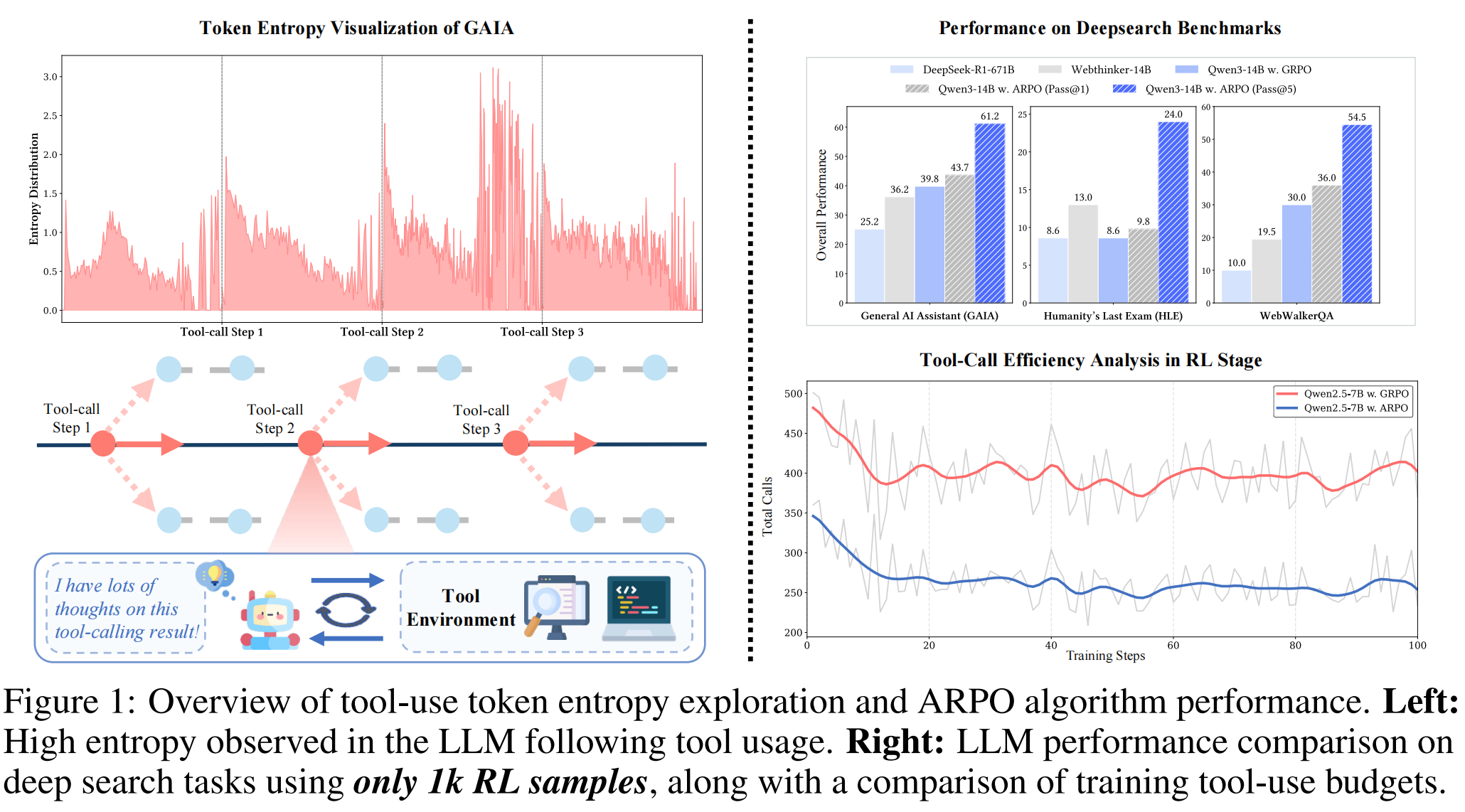
论文在深度搜索任务中发现:LLM 每次调用工具后,紧接着生成的 token 熵会急剧升高,前 10-50 个 token 的熵显著高于正常水平,之后才逐渐回落。原因很直观——搜索引擎返回的文本、Python 执行结果等外部信息,和模型内部状态之间存在分布偏移。工具反馈引入了不确定性,而Agentic RL 却把这些所有步骤一视同仁,这样就看不出哪次工具调用之后模型最需要后续探索"。论文提出了ARPO(Agentic Reinforced Policy Optimization)算法来专门解决这个问题。
2 方法
2.1 核心洞察:工具调用后的熵峰值
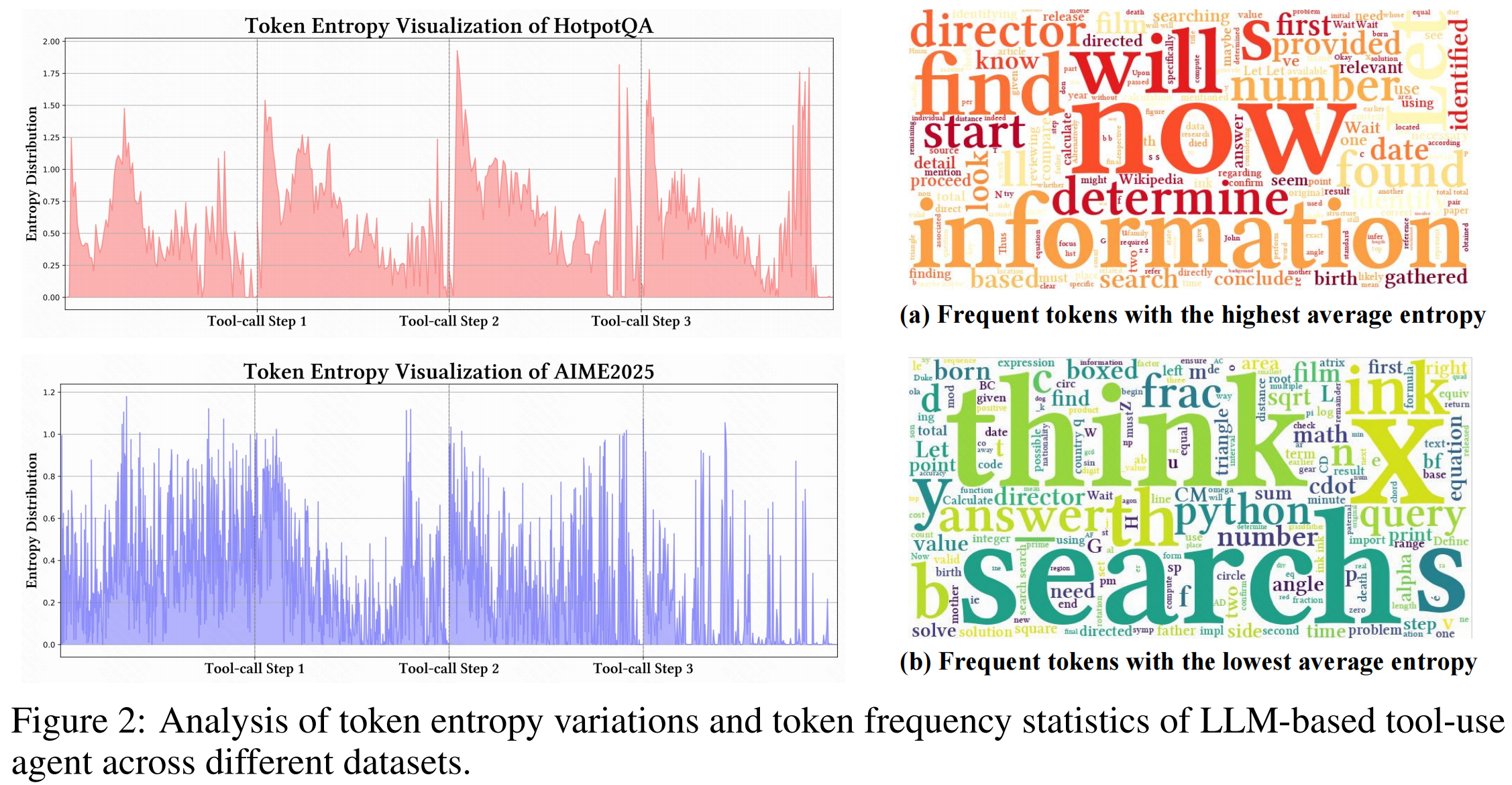
上图展示了 LLM Agent 在一次工具调用前后 token 熵的变化。很明显,在每次 [tool_call] 标记之后都会紧接着一段熵急剧升高的区域——这是因为模型面对工具返回的信息,需要重新组织推理。根据这个现象,论文提出了ARPO算法,其想法很直接:在熵高的地方多探索,在熵低的地方正常采样。
2.2 基于熵的自适应采样
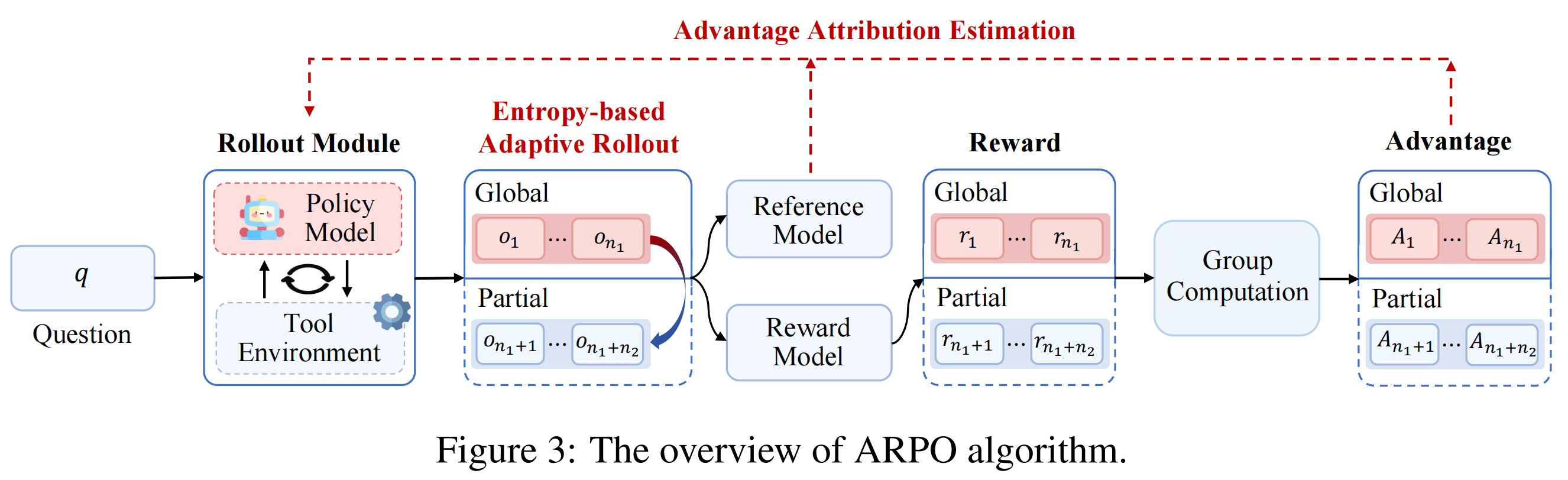
ARPO 的采样策略分两条线:Global rollout 采完整轨迹,Partial rollout 在高熵步骤做分支。具体四步:
(1)初始化:给定总采样预算 ,先用轨迹级采样生成 条完整轨迹,剩余 条预算留给后续分支。对每条轨迹的前 个 token 计算初始熵矩阵 。
(2)熵变监控:每条轨迹执行工具交互时,在每个工具调用步骤 之后让模型额外多生成 个 token,计算这一步的熵矩阵 ,然后算归一化的熵变化量:
表示这一步工具调用后不确定性增加, 表示减少。
(3)熵自适应分支:定义第 步的分支概率 ,当 超过阈值 时,从当前节点分叉出 条部分推理路径:
是基础采样概率, 控制熵变化量的权重。分支只重建从当前步骤开始的后续路径,不重建整条轨迹——共享前缀被复用,计算复杂度从轨迹级 RL 的 降到 到 之间。
(4)终止条件:要么分支数 达到预算 ,要么所有路径终止后补采剩余预算的轨迹级样本。
2.3 优势归因估计
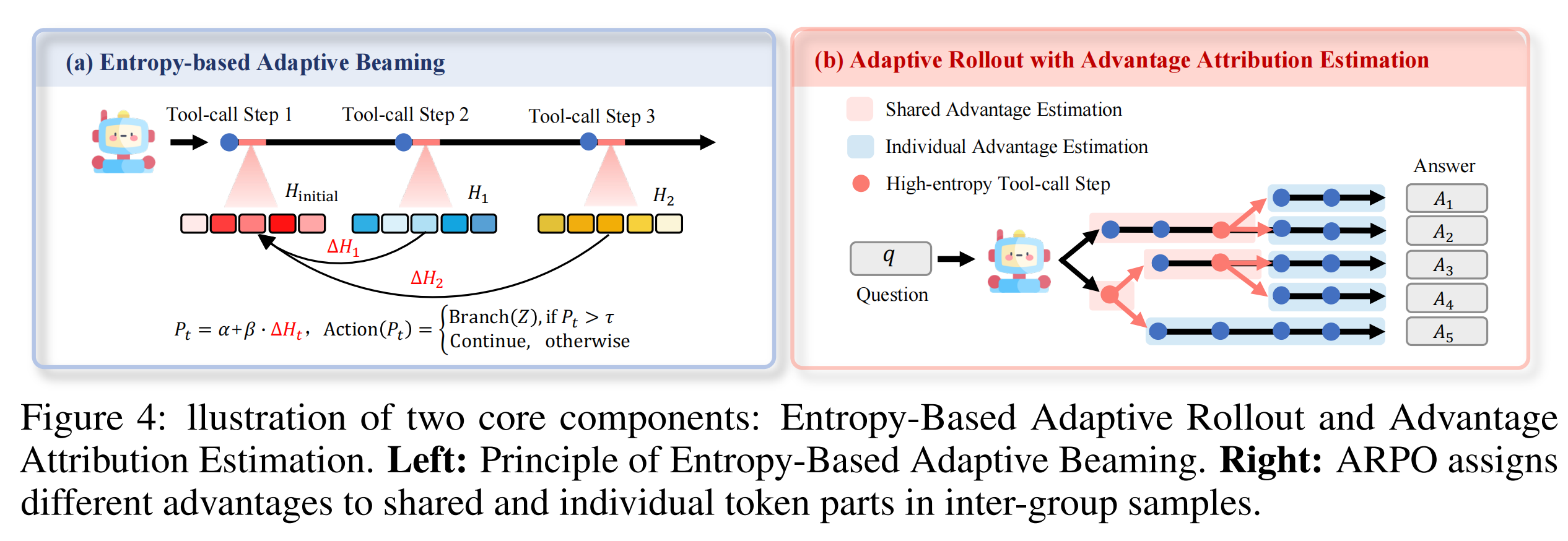
自适应采样产生了一个新结构:分叉前的 token 是共享的,分叉后的 token 各自独立。ARPO 的损失函数和 GRPO 相同:
其中 。核心差异在于 shared token 和 individual token 的 怎么算。
2.3.1 Hard Advantage Estimation
显式区分。独立 token 直接用该轨迹的归一化奖励:
共享 token 取包含该前缀的全部 条轨迹的 advantage 平均值:
本质上就是"分叉前大家平均,分叉后各算各的"。写死一条规则来区分,简单直接但需要额外逻辑处理。
2.3.2 Soft Advantage Estimation
Soft 的核心思想是:不显式做任何区分,让 GRPO 自身机制的计算流程自然完成Hard Advantage Estimation的流程。
具体来说,假设 A 和 B 两条轨迹在某个 tool-call 之前共享同一段前缀,之后分叉。在 GRPO 中,每条轨迹先独立算自己的 advantage:,。A 和 B 的 reward 不同,所以 。现在看共享前缀中的一个 token 。它在 A 中出现了一次,在 B 中也出现了一次。由于两次出现是完全同一个 token,重要性比率 自然相同。GRPO 做梯度更新时,这个 token 会收到来自 A 和 B 两路的梯度信号,加权后等效于用一个平均 advantage 来更新它——恰好就是 Hard 里显式算的 。而分叉后的独立 token只出现在自己那条轨迹里,没有"另一个版本的自己"来平均,所以它们各自保留独立的 advantage各自更新。
论文的实验验证了:Soft 不仅实现更简单,reward 曲线也比 Hard 更稳定,可能是额外的显式平均操作反而引入了一些数值偏差。
3 结论与感想
ARPO 是 Agentic RL 很著名的一个改进算法,核心洞察在于 Agent 调用工具后熵会急剧升高,采样策略应该跟着熵走。但代价也很明显——引入了大量额外超参,比如 (基础分支概率)、(熵变化权重)、(分支阈值)等,在轻量级应用上还有待改进。
Dong G, Mao H, Ma K, et al. Agentic Reinforced Policy Optimization[J]. arXiv preprint arXiv:2507.19849, 2025. ↩︎



