
SAPO
本文主要参考论文 [1]
1 背景与问题
强化学习(RL)已经成为提升 LLM 推理能力的关键手段。目前主流是基于分组的策略优化:对每个 query 采样 条回复,组内归一化 reward 得到 advantage ,再用 token 级重要性比率 加权更新:
表示当前策略相对于旧策略对第 个 token 的偏好变化—— 意味着当前策略更偏爱这个 token。GRPO 和 GSPO 是两个代表性方法,核心区别在于如何处理偏离 太远的 token:
- GRPO:token 级 PPO-clip,。 超出 的 token 梯度被截断。
- GSPO:既然奖励是针对整条序列的,那训练也应该针对整条序列进行。它将优化粒度从 token 级 提升到序列级,基于序列总体似然来定义整条回复的重要性比率,并在序列层面进行截剪,最后再去乘上对应的 Advantage。
硬截断的代价是: 越界就梯度归零,不分偏了多少。 只偏了一丁点,和 的极端离群 token 一样被完全截断无法回传梯度,大幅度降低了训练效率。SAPO则是用温度控制的软门控替代硬截断,让越界的token之间也分出差别来。
2 方法
2.1 核心公式
SAPO 的目标函数形式与 GRPO 一致,区别在于把 GRPO 中的截断操作替换为平滑的 sigmoid 门控函数。SAPO 最大化:
其中门控函数为:
是 sigmoid, 是温度参数。求导后得到梯度权重:
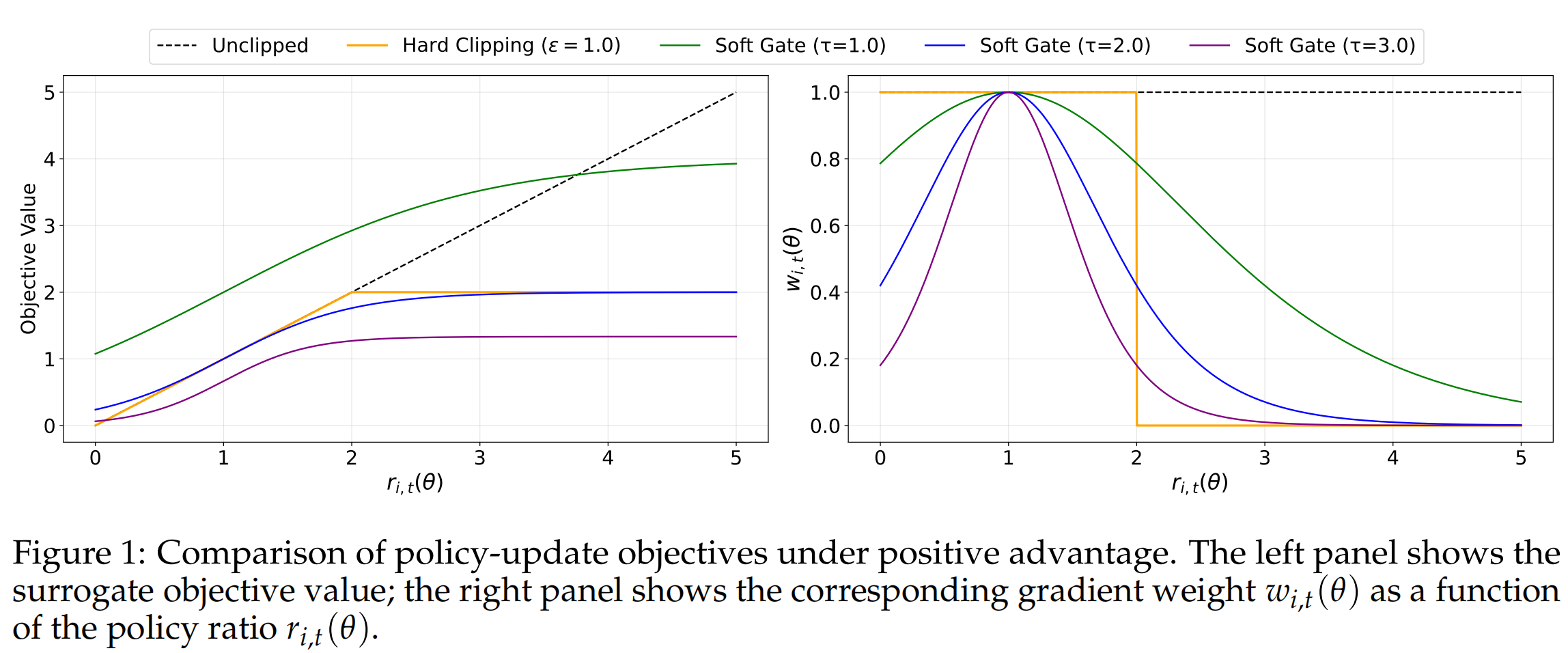
上图是正 advantage 情况,具体解读如下:
-
左图:目标函数值随 的变化。无截断的时候线性增长,硬截断则是()到 后拉平——超过就白超了,模型没有动力继续增大 。SAPO 软门控则逐渐趋近一个上限, 越大整体收益增量越小但不完全归零, 越大趋近上限越快。
-
右图:梯度权重 随 的变化。无截断时 恒定。硬截断()在 处从 1 断崖式跳到 0——边界上的 token 要么全算要么不算。SAPO 的权重是则是钟形曲线,在 附近和硬截断差不多,在远离 1 的区域平滑趋向 0 但不等于0——离群 token 的梯度被大幅压缩但仍有微弱信号。
2.2 不对称的温度
SAPO 对正负 advantage 的 token 使用不同温度:
且设定 (如 )。原因在于梯度传播机制:
对于正 advantage():梯度提高采样 token 的 logit、压低所有其他 token,方向集中。
对于负 advantage():梯度压低采样 token、提高大量未采样 token 的 logit。一个几十万 token 的词表里,只有 1 个是最优的,其余全是"不该选的"。负梯度会把 logit 扩散到大量无关 token 上,虽然提供了一些正则化但也极易引入不稳定因素。所以负 token 的衰减要更快,让离群的负 token 更新被更快压制。
2.3 在seqence-level和 token-level之间自动切换
SAPO 虽然是 token-level级别的算法,但论文证明了SAPO在正常条件下会自动表现为序列级更新。直觉上来看,如果策略还没跑偏太多,即重要性比率约等于1时,那把 token 级门控的结果平均之后,等价于对整条回复做一次统一的加权——和 GSPO 的序列级更新一致,只是截断从硬边界换成了平滑衰减。
当这个条件不满足时——比如序列中出现少数极度离群,重要性比率过高的 token——上述平均过程不再成立,离群 token 会拖偏平均结果。此时论文里证明SAPO 算法会自动保持 token-level门控,即仅压低那几个离群 token,其余 token 的更新不受影响。
3 结论与感想
SAPO 的改进本质上就是把硬性clip改成软性clip。一个值得注意的点是一般设置 而 ,差距只有 0.05。但消融实验显示如果反过来()训练直接崩——负 token 更新的不稳定性远比想象的严重,0.05 的温差就足以决定训练成败。
另外,有关这种RL后训练改进的算法一般原文都会有很多复杂的数学推导,我这里为了博客观感没有放,感兴趣的可以去看一下原文
Gao C, Zheng C, Chen X H, et al. Soft adaptive policy optimization[J]. arXiv preprint arXiv:2511.20347, 2025. ↩︎
