
Qwen2.5VL技术报告
本文内容主要来自Qwen2.5VL技术报告[1]
1 背景与介绍
目前的视觉语言模型面临几大发展瓶颈,包括:计算复杂度高、上下文理解受限、细粒度(fine-grained)视觉感知能力差,以及在处理不同长度序列时性能不一致。为了突破上述瓶颈,Qwen2.5-VL 致力于探索细粒度的感知能力,将其作为模型的坚实基础层;同时,利用最新的 Qwen2.5 大语言模型并构建多模态问答数据,来强化模型的多模态推理能力。
论文明确提出了 Qwen2.5-VL 在技术上的四个主要创新点:
- 优化视觉编码器: 在视觉编码器中实现了窗口注意力机制(window attention),从而优化了推理效率。
- 动态 FPS 采样: 引入了动态帧率(FPS)采样,将动态分辨率扩展到了时间维度,使模型能够全面理解不同采样率的视频。
- 时间与“绝对时间”对齐: 升级了时间维度的 MROPE(多模态旋转位置编码),将其与“绝对时间”对齐,从而促进了更复杂的时间序列学习。
- 海量高质量数据: 在精选高质量预训练和监督微调数据方面做出了巨大努力,将预训练语料库从 1.2 万亿 Token 大幅扩展到了 4.1 万亿 Token。
2 方法
2.1 模型架构
Qwen2.5-VL 的架构由经典的视觉-语言三段式组成:LLM 负责理解推理,ViT 负责视觉编码,中间的融合器负责把两种模态对齐。LLM 从 Qwen2.5 权重初始化,ViT 从头训练。完整配置如下:
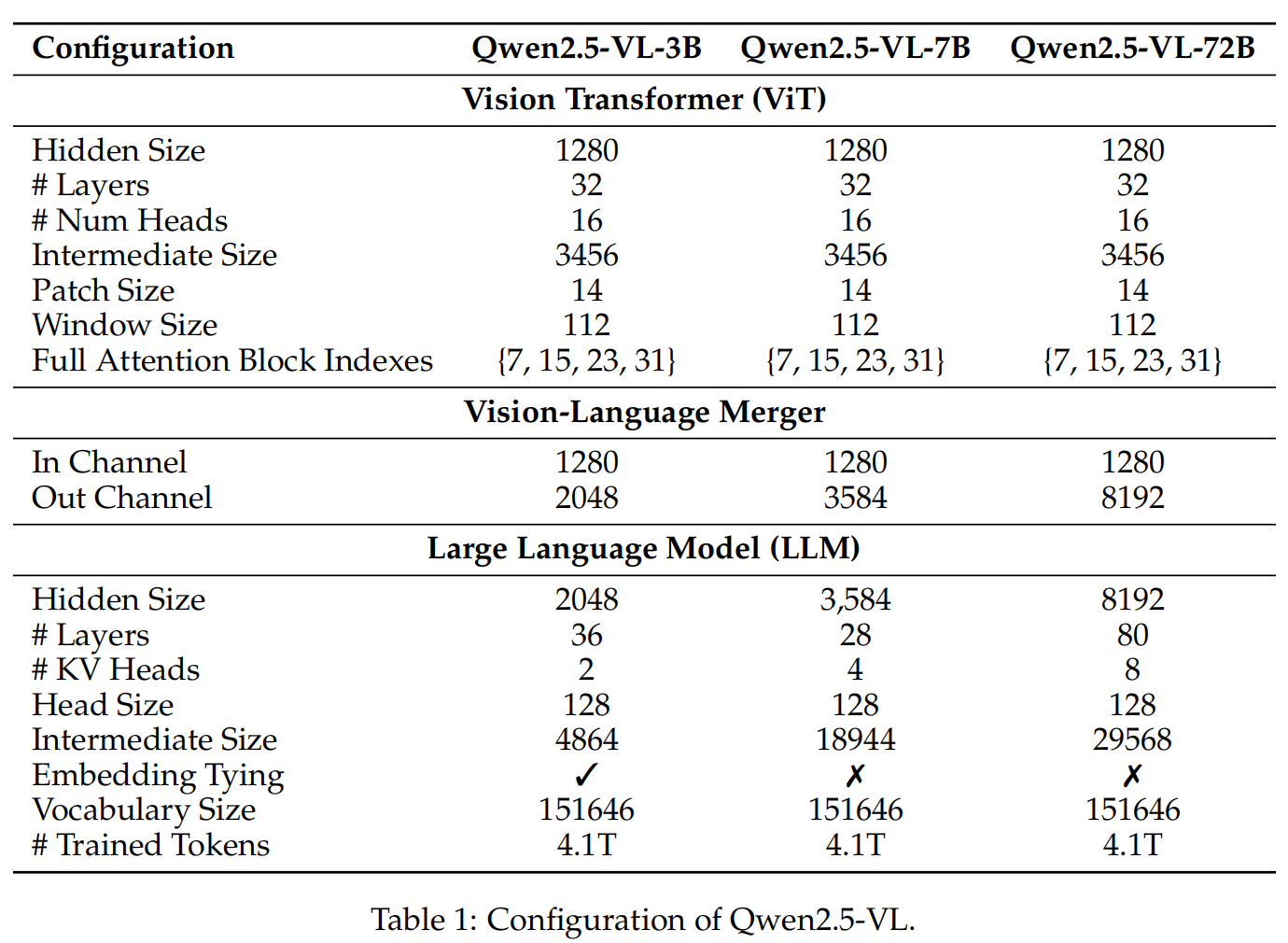
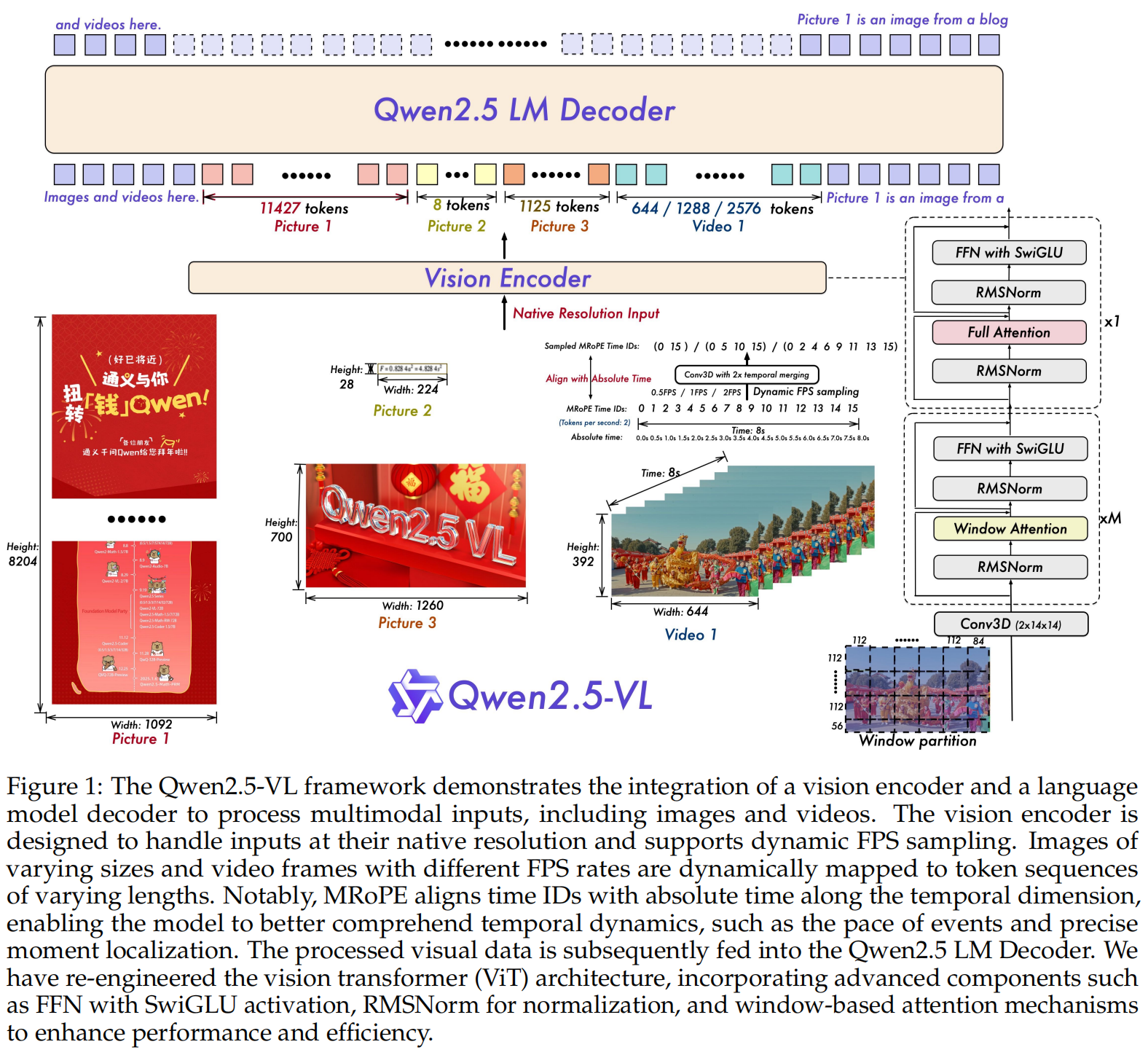
2.1.1 视觉编码器
ViT (是一个patch)并不是用预先训练好的成品,而是从头训练,并且所有模型规格共用同一套。核心目标是在原生分辨率输入的条件下维持高效推理。主要设计要点如下:
- 原生动态分辨率:传统 VLM 把所有图像 resize 到固定方图(如 ),每张图产生固定数量的 token。Qwen2.5-VL 则是 resize 到 28 的倍数(正好是2倍的Vit 的 patch size, 因为后面MLP要做 空间压缩)且保留原始宽高比——比如一张 的图会调整为约 ,而非强制正方形。结果是高分辨率图多出 token、低分辨率图少出 token,序列长度动态变化。
- 窗口注意力:图像以原生分辨率输入时,不同尺寸产生的 patch 数差异巨大,全量自注意力 导致负载极不均衡。解法是 32 层中仅 4 层用全量自注意力,其余 28 层限制在 像素的窗口内,注意每个窗口是不重叠的块划分,不是滑动的,这样注意力计算复杂度才能降到 。对于图像边缘凑不满 的残余区域,不补零填充而是直接用其原生尺寸做注意力。
- 2D-RoPE:将特征维度拆开,分别编码每个 patch 的行列坐标,目的是使模型天然感知图片的空间位置。
- 视频输入的特殊处理:视频输入时使用动态FPS采样,并且时间上把连续的两帧打包为一个patch ,大幅减少送入 LLM 的 token 数。
- 架构对齐 LLM:采用 RMSNorm 归一化层与 SwiGLU 激活函数,与LLM部分保持一致,让视觉编码器和语言大脑更契合。
2.1.2 视觉-语言融合器
将 ViT 输出的视觉特征映射到 LLM 嵌入维度,设计追求轻量高效,主要内容如下:
- 空间压缩:把空间上相邻的 4 个 patch 特征拼接为一个长向量( 维),token 数直接砍到 1/4。
- 两层 MLP 投影:压缩后的向量主要经过两层 MLP 投影到 LLM 维度。
2.1.3 大语言模型
LLM 从 Qwen2.5 权重初始化,所有规格使用 GQA,预训练 4.1T tokens。核心改造是MRoPE(多模态旋转位置编码):
- 将位置编码拆为时间、高度、宽度三个独立通道,同一套参数适配三种模态:
- 文本:三通道 ID 相同 → 等价 1D-RoPE。
- 图像:时间 ID 恒定,高宽按行列坐标分配。
- 视频:时间 ID 随帧递增,高宽沿用图像规则。
- Qwen2.5-VL 将时间分量直接与绝对时间对齐——ID 间隔始终反映真实时间流逝,模型能理解事件节奏,零额外开销。
2.2 预训练
预训练分三个阶段,数据量和上下文长度逐步递增:
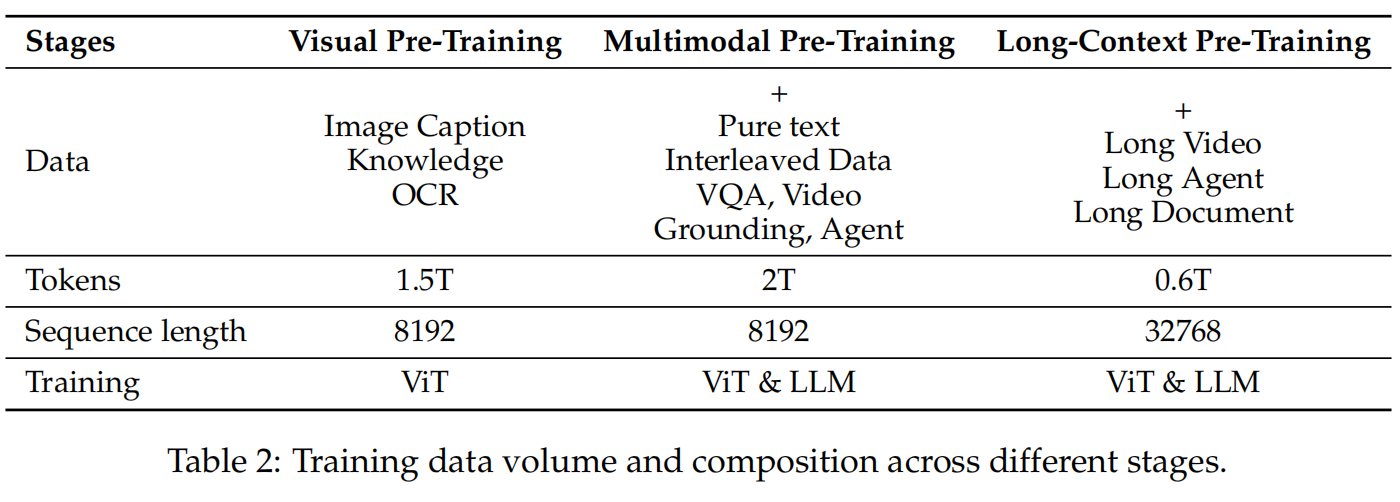
第一阶段冻结 LLM,只训 ViT,目的是让视觉编码器先学会提取与语言模型可对齐的特征。第二阶段解冻全部参数,加入更复杂的多模态推理数据——VQA、数学、Agent 交互、视频理解——建立视觉与语言之间的深层连接。第三阶段把上下文从 8192 拉到 32768,辅以长视频、长轨迹、长文档数据,让模型处理超长序列。
训练效率方面,不同图像尺寸和文本长度会导致各 GPU 的计算负载不均衡。由于 ViT 参数少且窗口注意力已大幅降低其计算量,论文的策略是按 LLM 的输入序列长度动态拼接样本(dynamic packing),使每个 GPU 的计算量尽量均匀。
2.3 后训练
后训练分两阶段:SFT 和 DPO,ViT 在两个阶段均冻结。SFT 数据的构建包含三步:
- 数据收集:约 200 万条指令数据,纯文本和多模态各 50%。中英文为主,辅以多语言。单轮和多轮对话,单图到多图序列。领域覆盖 VQA、caption、数学、编程、文档/OCR、grounding、视频、Agent。
- 数据清洗:两阶段过滤——规则过滤(去重、去截断、去格式错误、去有害内容)和模型过滤(用 reward 模型对 QA 做多维度打分:query 复杂度/相关性,answer 正确性/完整性/清晰度/有用性,grounding 任务额外验证视觉信息准确使用)。
- 拒绝采样增强推理:另外还有一部分数据,是用预训练完的中间版本的 Qwen2.5-VL,让它对数学、编程等有标准答案的任务生成 CoT 推理过程,只保留最终答案与 ground truth 匹配的样本,再剔除语言切换、过长回复、重复模式等。视觉相关的额外用规则+模型验证中间步骤有没有正确用到图像信息。筛选后的高质量样本再用于最终 SFT 训练。
DPO在 SFT 之后进行,仅使用图文和纯文本数据,利用偏好数据对齐人类偏好,每个样本只处理一次。
3 总结与感想
Qwen2.5VL感觉还是很经典的一个模型,可以看出qwen团队在这个模型做出了很多改进,比如窗口注意力,MRope等,值得一读的技术报告。
Bai S, Chen K, Liu X, et al. Qwen2.5-VL Technical Report[J]. arXiv preprint arXiv:2502.13923, 2025. ↩︎

